 English
English Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 on All Hosting Services
on All Hosting ServicesHow to Find a File by Content in Linux: grep, find, and awk Explained
Searching for a file by its content in Linux means scanning file data — not just filenames or metadata — using tools like grep, find, and awk to match text patterns, strings, or regular expressions across one or many files simultaneously. This is fundamentally different from name-based searches and is the correct approach when you know what a file *contains* but not where it lives or what it is called.
For anyone managing a VPS Hosting environment, content-based file search is a daily operational necessity: locating misconfigured directives in /etc, auditing log files for error patterns, or hunting down hardcoded credentials in application source trees. The commands covered in this guide work identically across all major Linux distributions — Debian, Ubuntu, CentOS, AlmaLinux, and Arch — with no additional packages required.
Why Content-Based Search Matters in Linux Environments
Filename-based searches (ls, locate) tell you nothing about what a file contains. In production systems, the critical questions are almost always content-driven:
- Which config file sets
max_connectionsto a specific value? - Which PHP file contains a deprecated function call that is throwing warnings?
- Which log file recorded a specific IP address at a given timestamp?
- Which cron job definition references a now-deleted script path?
Modern file managers and GUI search tools cannot answer these questions efficiently at scale. The Linux command line can — and does so in milliseconds across millions of files when used correctly.
The grep Command: Primary Tool for Content Search
grep (Global Regular Expression Print) is the canonical tool for searching file content in Linux. It reads files line by line and prints any line matching a given pattern.
Core Syntax
grep [OPTIONS] PATTERN [FILE_OR_DIRECTORY]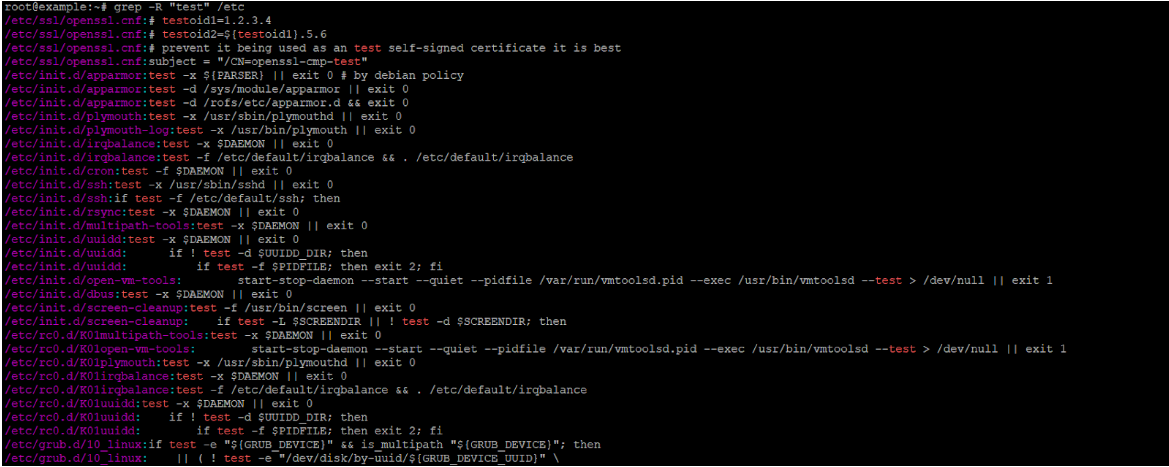
Recursive Directory Search
The most common real-world usage is a recursive search across an entire directory tree:
grep -rnw '/path/to/directory/' -e 'search_text'Breaking down each flag:
| Flag | Full Name | Effect |
|---|---|---|
-r | --recursive | Descends into subdirectories automatically |
-n | --line-number | Prepends the matching line's number to output |
-w | --word-regexp | Matches whole words only — test will not match testing |
-e | --regexp | Explicitly declares the search pattern; required when the pattern begins with a hyphen |
-i | --ignore-case | Case-insensitive matching (Error matches error, ERROR) |
-l | --files-with-matches | Prints only filenames, not the matching lines |
-c | --count | Prints only the count of matching lines per file |
-v | --invert-match | Returns lines that do NOT match the pattern |
-A N | --after-context=N | Shows N lines after each match for context |
-B N | --before-context=N | Shows N lines before each match for context |
--include | N/A | Restricts search to files matching a glob pattern |
--exclude | N/A | Skips files matching a glob pattern |
Practical grep Examples
Search for the string "test1" inside /usr/games and all subdirectories:
grep -r "test1" /usr/gamesFind all files under /etc that contain the word "network" (whole word, case-insensitive), showing line numbers:
grep -rniw "network" /etcList only the filenames (not matching lines) of PHP files containing eval(:
grep -rl "eval(" /var/www/html --include="*.php"Search for a pattern and display 3 lines of context before and after each match:
grep -rn -A 3 -B 3 "FATAL" /var/log/Count how many times "PermitRootLogin" appears across all SSH config files:
grep -rc "PermitRootLogin" /etc/ssh/Find lines that do NOT contain "localhost" in a hosts file:
grep -v "localhost" /etc/hostsgrep with Regular Expressions
grep supports three regex engines:
- BRE (Basic Regular Expressions) — default mode
- ERE (Extended Regular Expressions) — activated with
-Eoregrep - PCRE (Perl-Compatible Regular Expressions) — activated with
-P
# Match lines containing an IPv4 address pattern (ERE)
grep -rE '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/nginx/access.log
# Match lines with email addresses (PCRE)
grep -rP '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}' /var/www/html/Critical Edge Cases and Pitfalls with grep
Binary files: By default, grep will print Binary file X matches for binary files and skip their content. Use -a (--text) to force grep to treat binary files as text — useful when searching compiled configs or database dumps. Use with caution on large binaries.
Symlinks: -r does not follow symbolic links. Use -R (capital R) to follow symlinks recursively. Be aware this can create infinite loops if circular symlinks exist.
Performance on large trees: grep is single-threaded by default. For massive codebases (millions of files), consider ripgrep (rg) or ag (The Silver Searcher), which are multi-threaded and respect .gitignore patterns automatically.
Null bytes in filenames: Pipe find output with -print0 and use grep --null or xargs -0 to handle filenames containing spaces or special characters safely.
Encoding issues: grep operates on bytes, not characters. If files use UTF-16 or other encodings, results may be unreliable. Set LANG=C or LC_ALL=C before the command to force byte-level matching:
LC_ALL=C grep -r "pattern" /path/The find Command: Combining File Metadata and Content Search
While grep searches *within* files, find locates files based on their metadata — name, type, size, permissions, modification time — and can then execute arbitrary commands on each result. Combining find with grep gives you precise, multi-criteria content searches.
Core Syntax
find /starting/path [CRITERIA] [ACTION]Content Search Using find + grep
find /path/to/directory/ -type f -exec grep -l 'search_text' {} ;Anatomy of this command:
| Component | Meaning |
|---|---|
/path/to/directory/ | Root directory for the search |
-type f | Restricts results to regular files only (excludes directories, sockets, devices) |
-exec ... {} ; | Executes the specified command once per matched file; {} is replaced by the filename |
grep -l | Prints only the filename if a match is found, not the matching line |
Combining find Criteria for Precision
The real power of find is layering multiple criteria before executing grep, dramatically reducing the number of files that need to be scanned:
Search only .conf files modified in the last 7 days:
find /etc -type f -name "*.conf" -mtime -7 -exec grep -l "timeout" {} ;Search only files larger than 1MB:
find /var/log -type f -size +1M -exec grep -c "ERROR" {} ;Search files owned by a specific user:
find /home -type f -user john -exec grep -l "password" {} ;Search files with specific permissions (world-writable):
find /var/www -type f -perm -o+w -exec grep -l "eval(" {} ;Exclude a directory from the search:
find /var/www -type f -not -path "*/node_modules/*" -exec grep -l "API_KEY" {} ;Using find with xargs for Better Performance
The -exec ... ; syntax spawns a new process for every single file found. On directories with thousands of files, this is measurably slower. Using xargs batches multiple filenames into a single grep invocation:
find /path/ -type f -name "*.log" -print0 | xargs -0 grep -l "connection refused"The -print0 and -0 flags use null characters as delimiters instead of newlines, correctly handling filenames with spaces.
The awk Command: Structured Content Search and Extraction
awk is a full text-processing language, not just a search tool. It excels when you need to search for patterns within structured files — CSV data, log files with fixed columns, configuration files — and simultaneously extract, transform, or calculate from the matched data.
Core Syntax
awk '/pattern/ { action }' filePractical awk Examples for File Content Search
Print all lines in a file containing the word "error":
awk '/error/' /var/log/syslogSearch for a pattern and print only specific fields (column 1 and column 5):
awk '/FAILED/ { print $1, $5 }' /var/log/auth.logSearch across multiple files and print the filename with matching lines:
awk '/search_term/ { print FILENAME": "$0 }' /etc/nginx/*.confCase-insensitive search in awk:
awk 'tolower($0) ~ /timeout/' /etc/mysql/my.cnfCount occurrences of a pattern per file:
awk '/ERROR/ { count++ } END { print FILENAME, count }' /var/log/app.logWhen to Use awk Instead of grep
awk is the better choice when:
- You need to filter by column value (e.g., "find lines where field 3 is greater than 500")
- You need to perform arithmetic on matched data
- You need to aggregate results (counts, sums) across a file
- The file has a consistent delimiter and you need structured extraction
grep remains faster for pure pattern-matching tasks where you only need to know *if* and *where* a pattern exists.
Tool Comparison: grep vs find vs awk
| Criterion | grep | find + grep | awk |
|---|---|---|---|
| Primary purpose | Content pattern matching | Metadata-filtered content search | Structured data processing |
| Recursive search | Yes (-r / -R) | Yes (native) | No (requires shell loop) |
| Metadata filtering | No | Yes (name, size, date, owner) | No |
| Regular expression support | BRE, ERE, PCRE | Via grep | ERE |
| Output formatting | Limited | Limited | Full programmable control |
| Performance on large trees | Fast | Slower (process-per-file) | Moderate |
| Learning curve | Low | Medium | High |
| Best use case | Quick keyword search | Multi-criteria production audits | Log parsing, data extraction |
Advanced Techniques for Production Environments
Searching Compressed Log Files
On servers where logs are rotated and compressed, use zgrep to search .gz files without decompressing them first:
zgrep "segfault" /var/log/syslog.*.gzSearching Inside tar Archives Without Extracting
tar -xOf archive.tar.gz | grep "search_pattern"Combining grep with sort and uniq for Frequency Analysis
Find the most common error messages in a log file:
grep "ERROR" /var/log/app.log | sort | uniq -c | sort -rn | head -20Excluding Binary Files and Focusing on Source Code
grep -r --include="*.py" --include="*.js" --include="*.php" "TODO" /var/www/Real-Time Content Monitoring with grep
Pipe tail -f into grep to monitor live log output for specific patterns:
tail -f /var/log/nginx/error.log | grep --line-buffered "upstream"The --line-buffered flag forces grep to flush output after each line, which is essential when piping from a continuous stream.
Security Auditing Use Cases
Content-based file search is a core technique in Linux security hardening. On a Dedicated Server or VPS, these patterns are operationally critical:
Scan for hardcoded passwords in web application files:
grep -rniE "(password|passwd|pwd)s*=s*['"][^'"]{3,}" /var/www/ --include="*.php"Find world-readable private key files:
find / -name "*.pem" -o -name "*.key" | xargs grep -l "PRIVATE KEY"Detect PHP webshells by scanning for common shell function combinations:
grep -rPl "evals*(s*(base64_decode|gzinflate|str_rot13)" /var/www/Audit SSH authorized_keys files across all users:
find /home -name "authorized_keys" -exec grep -H "." {} ;When running a VPS with cPanel, these audits are particularly important because cPanel environments host multiple accounts and a compromise in one can affect others.
Performance Optimization for Large-Scale Searches
Limit search depth to avoid traversing deep directory trees unnecessarily:
find /var/www -maxdepth 3 -type f -name "*.php" -exec grep -l "eval(" {} ;Use ripgrep for speed-critical tasks. While not covered in depth here, rg is 3–10x faster than grep on large codebases due to parallelism and smarter file filtering. It is available in most distribution repositories:
apt install ripgrep # Debian/Ubuntu
yum install ripgrep # CentOS/RHELProfile your search with time to benchmark different approaches:
time grep -r "pattern" /large/directory/Avoid searching /proc and /sys — these virtual filesystems can cause hangs or produce meaningless output:
grep -r --exclude-dir={proc,sys,dev} "pattern" /Choosing the Right Approach: Decision Matrix
| Scenario | Recommended Command | |
|---|---|---|
| Quick keyword search in a directory | grep -rn "keyword" /path/ | |
| Case-insensitive whole-word search | grep -rniw "keyword" /path/ | |
| Search only specific file types | grep -r --include="*.conf" "keyword" /path/ | |
| Search files modified recently | find /path -mtime -1 -exec grep -l "keyword" {} ; | |
| Search large file trees efficiently | `find /path -print0 | xargs -0 grep -l "keyword"` |
| Extract structured data from logs | awk '/pattern/ { print $1, $NF }' logfile | |
| Search compressed logs | zgrep "keyword" /var/log/*.gz | |
| Real-time log monitoring | `tail -f /var/log/file.log | grep –line-buffered "pattern"` |
| Security audit for sensitive strings | grep -rPl "eval(base64_decode" /var/www/ |
Key Technical Takeaways
- Use
grep -rniwas your default recursive search — it handles case, whole words, and line numbers in one pass. - Always use
-print0withfindand-0withxargsto handle filenames containing spaces or special characters. - Use
-exec grep ... {} +(plus sign instead of semicolon) to batch multiple files pergrepinvocation and reduce process overhead. grep -R(capital R) follows symlinks;grep -rdoes not — know which behavior your environment requires.- Set
LC_ALL=Cbeforegrepin scripts to avoid locale-related performance penalties and encoding surprises. - Restrict searches using
--includeand--exclude-dirto eliminate irrelevant files before pattern matching begins. - For multi-account hosting environments managed through VPS Control Panels, schedule content audits as cron jobs using these commands to automate security checks.
- On Shared Web Hosting environments, content search permissions may be restricted by the hosting provider — use these commands within your own account's file tree only.
Frequently Asked Questions
What is the fastest way to search for text in all files on a Linux server?
For speed on large file trees, use grep -r --include="*.ext" "pattern" /path/ with file type restrictions, or install ripgrep (rg "pattern" /path/) which uses multi-threading and is typically 3–10x faster than standard grep on large codebases.
How do I search for a string in files but exclude certain directories?
Use grep's --exclude-dir option: grep -r --exclude-dir={.git,node_modules,vendor} "pattern" /path/. For find-based searches, use -not -path "*/dirname/*" before the -exec clause.
What is the difference between grep -r and grep -R?
grep -r performs a recursive search but does not follow symbolic links. grep -R performs the same recursive search and additionally follows symlinks. Use -R only when you are certain no circular symlinks exist in the target directory tree.
Can I search for content inside compressed .gz log files without decompressing them?
Yes. Use zgrep "pattern" /var/log/file.log.gz for individual files, or zgrep "pattern" /var/log/*.gz for multiple compressed files. The output format is identical to standard grep.
How do I search for a multi-line pattern in Linux files?
Standard grep matches line by line and cannot natively match patterns spanning multiple lines. Use grep -P with Perl-compatible regex and n for newlines, or use pcregrep -M "line1nline2" file if pcregrep is available. For complex multi-line extraction, awk with RS (record separator) redefinition is often the most readable solution.


