 Русский
Русский English
English  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 на всех хостинговых услугах
на всех хостинговых услугахКак найти файл по содержимому в Linux: объяснение grep, find и awk
Поиск файла по его содержимому в Linux означает сканирование данных файла — не только имён файлов или метаданных — с использованием таких инструментов, как grep, find и awk для сопоставления текстовых шаблонов, строк или регулярных выражений в одном или нескольких файлах одновременно. Это принципиально отличается от поиска по имени и является правильным подходом, когда вы знаете, что файл *содержит*, но не знаете, где он находится или как называется.
Для всех, кто управляет средой VPS Хостинга, поиск файлов по содержимому является ежедневной операционной необходимостью: поиск неправильно настроенных директив в /etc, аудит лог-файлов на предмет шаблонов ошибок или поиск жёстко заданных учётных данных в деревьях исходного кода приложений. Команды, рассмотренные в этом руководстве, работают одинаково во всех основных дистрибутивах Linux — Debian, Ubuntu, CentOS, AlmaLinux и Arch — без необходимости установки дополнительных пакетов.
Почему поиск по содержимому важен в среде Linux
Поиск по имени файла (ls, locate) ничего не говорит о содержимом файла. В производственных системах критически важные вопросы почти всегда связаны с содержимым:
- Какой конфигурационный файл устанавливает
max_connectionsв определённое значение? - Какой PHP-файл содержит вызов устаревшей функции, вызывающей предупреждения?
- Какой лог-файл зафиксировал определённый IP-адрес в заданное время?
- Какое определение задания cron ссылается на удалённый путь к скрипту?
Современные файловые менеджеры и инструменты поиска с графическим интерфейсом не могут эффективно отвечать на эти вопросы в масштабе. Командная строка Linux может — и делает это за миллисекунды среди миллионов файлов при правильном использовании.
Команда grep: основной инструмент для поиска по содержимому
grep (Global Regular Expression Print) — это стандартный инструмент для поиска содержимого файлов в Linux. Он читает файлы построчно и выводит любую строку, соответствующую заданному шаблону.
Основной синтаксис
grep [OPTIONS] PATTERN [FILE_OR_DIRECTORY]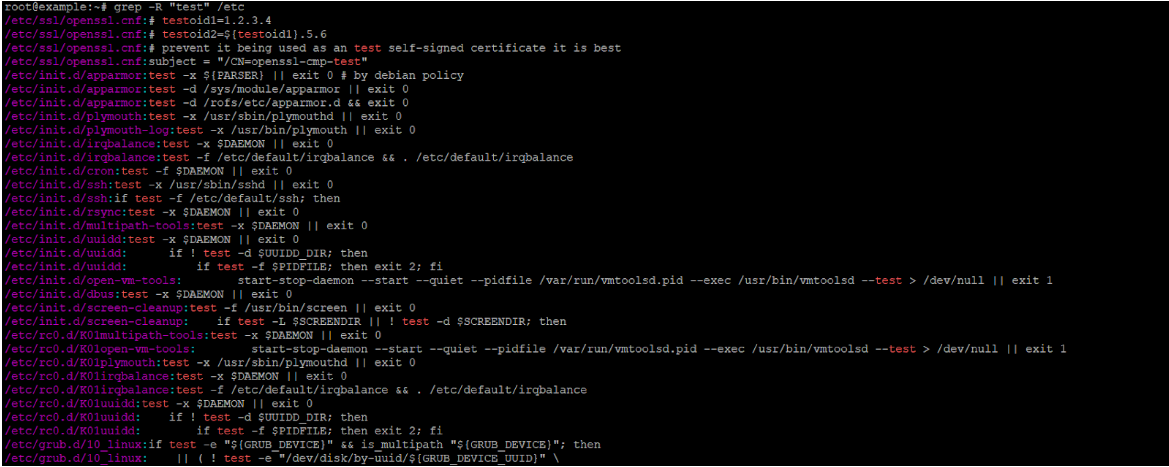
Рекурсивный поиск по директории
Наиболее распространённое реальное использование — рекурсивный поиск по всему дереву директорий:
grep -rnw '/path/to/directory/' -e 'search_text'Описание каждого флага:
| Флаг | Полное название | Действие |
|---|---|---|
-r | --recursive | Автоматически спускается в поддиректории |
-n | --line-number | Добавляет номер совпадающей строки к выводу |
-w | --word-regexp | Сопоставляет только целые слова — test не будет соответствовать testing |
-e | --regexp | Явно объявляет шаблон поиска; требуется, когда шаблон начинается с дефиса |
-i | --ignore-case | Поиск без учёта регистра (Error соответствует error, ERROR) |
-l | --files-with-matches | Выводит только имена файлов, а не совпадающие строки |
-c | --count | Выводит только количество совпадающих строк на файл |
-v | --invert-match | Возвращает строки, которые НЕ соответствуют шаблону |
-A N | --after-context=N | Показывает N строк после каждого совпадения для контекста |
-B N | --before-context=N | Показывает N строк перед каждым совпадением для контекста |
--include | N/A | Ограничивает поиск файлами, соответствующими шаблону glob |
--exclude | N/A | Пропускает файлы, соответствующие шаблону glob |
Практические примеры grep
Поиск строки "test1" внутри /usr/games и всех поддиректорий:
grep -r "test1" /usr/gamesНайти все файлы в /etc, содержащие слово "network" (целое слово, без учёта регистра), с отображением номеров строк:
grep -rniw "network" /etcВывести только имена файлов (без совпадающих строк) PHP-файлов, содержащих eval(:
grep -rl "eval(" /var/www/html --include="*.php"Поиск шаблона с отображением 3 строк контекста до и после каждого совпадения:
grep -rn -A 3 -B 3 "FATAL" /var/log/Подсчитать, сколько раз "PermitRootLogin" встречается во всех конфигурационных файлах SSH:
grep -rc "PermitRootLogin" /etc/ssh/Найти строки, НЕ содержащие "localhost" в файле hosts:
grep -v "localhost" /etc/hostsgrep с регулярными выражениями
grep поддерживает три движка регулярных выражений:
- BRE (базовые регулярные выражения) — режим по умолчанию
- ERE (расширенные регулярные выражения) — активируется с помощью
-Eилиegrep - PCRE (Perl-совместимые регулярные выражения) — активируется с помощью
-P
# Match lines containing an IPv4 address pattern (ERE)
grep -rE '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/nginx/access.log
# Match lines with email addresses (PCRE)
grep -rP '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}' /var/www/html/Критические граничные случаи и подводные камни grep
Бинарные файлы: По умолчанию grep выведет Binary file X matches для бинарных файлов и пропустит их содержимое. Используйте -a (--text), чтобы заставить grep обрабатывать бинарные файлы как текст — это полезно при поиске в скомпилированных конфигурациях или дампах баз данных. Используйте с осторожностью на больших бинарных файлах.
Символические ссылки: -r не следует по символическим ссылкам. Используйте -R (заглавная R) для рекурсивного следования по символическим ссылкам. Имейте в виду, что это может создать бесконечные циклы при наличии циклических символических ссылок.
Производительность на больших деревьях: grep по умолчанию однопоточный. Для массивных кодовых баз (миллионы файлов) рассмотрите ripgrep (rg) или ag (The Silver Searcher), которые многопоточны и автоматически учитывают шаблоны .gitignore.
Нулевые байты в именах файлов: Передавайте вывод find через -print0 и используйте grep --null или xargs -0 для безопасной обработки имён файлов, содержащих пробелы или специальные символы.
Проблемы с кодировкой: grep работает с байтами, а не символами. Если файлы используют UTF-16 или другие кодировки, результаты могут быть ненадёжными. Установите LANG=C или LC_ALL=C перед командой для принудительного сопоставления на уровне байтов:
LC_ALL=C grep -r "pattern" /path/Команда find: объединение метаданных файлов и поиска по содержимому
В то время как grep выполняет поиск *внутри* файлов, find находит файлы на основе их метаданных — имени, типа, размера, прав доступа, времени изменения — и может затем выполнять произвольные команды для каждого результата. Объединение find с grep даёт точный поиск по содержимому с несколькими критериями.
Основной синтаксис
find /starting/path [CRITERIA] [ACTION]Поиск по содержимому с использованием find + grep
find /path/to/directory/ -type f -exec grep -l 'search_text' {} ;Анатомия этой команды:
| Компонент | Значение |
|---|---|
/path/to/directory/ | Корневая директория для поиска |
-type f | Ограничивает результаты только обычными файлами (исключает директории, сокеты, устройства) |
-exec ... {} ; | Выполняет указанную команду для каждого найденного файла; {} заменяется именем файла |
grep -l | Выводит только имя файла при обнаружении совпадения, а не совпадающую строку |
Объединение критериев find для точности
Реальная мощь find заключается в наложении нескольких критериев перед выполнением grep, что значительно сокращает количество файлов, которые необходимо сканировать:
Поиск только в файлах .conf, изменённых за последние 7 дней:
find /etc -type f -name "*.conf" -mtime -7 -exec grep -l "timeout" {} ;Поиск только в файлах размером более 1MB:
find /var/log -type f -size +1M -exec grep -c "ERROR" {} ;Поиск в файлах, принадлежащих определённому пользователю:
find /home -type f -user john -exec grep -l "password" {} ;Поиск в файлах с определёнными правами доступа (доступных для записи всем):
find /var/www -type f -perm -o+w -exec grep -l "eval(" {} ;Исключить директорию из поиска:
find /var/www -type f -not -path "*/node_modules/*" -exec grep -l "API_KEY" {} ;Использование find с xargs для повышения производительности
Синтаксис -exec ... ; создаёт новый процесс для каждого найденного файла. В директориях с тысячами файлов это заметно медленнее. Использование xargs объединяет несколько имён файлов в один вызов grep:
find /path/ -type f -name "*.log" -print0 | xargs -0 grep -l "connection refused"Флаги -print0 и -0 используют нулевые символы в качестве разделителей вместо символов новой строки, корректно обрабатывая имена файлов с пробелами.
Команда awk: структурированный поиск и извлечение содержимого
awk — это полноценный язык обработки текста, а не просто инструмент поиска. Он превосходит другие инструменты, когда нужно искать шаблоны в структурированных файлах — данных CSV, лог-файлах с фиксированными столбцами, конфигурационных файлах — и одновременно извлекать, преобразовывать или вычислять данные из найденных совпадений.
Основной синтаксис
awk '/pattern/ { action }' fileПрактические примеры awk для поиска содержимого файлов
Вывести все строки в файле, содержащие слово "error":
awk '/error/' /var/log/syslogПоиск шаблона и вывод только определённых полей (столбец 1 и столбец 5):
awk '/FAILED/ { print $1, $5 }' /var/log/auth.logПоиск по нескольким файлам с выводом имени файла и совпадающих строк:
awk '/search_term/ { print FILENAME": "$0 }' /etc/nginx/*.confПоиск без учёта регистра в awk:
awk 'tolower($0) ~ /timeout/' /etc/mysql/my.cnfПодсчёт вхождений шаблона на файл:
awk '/ERROR/ { count++ } END { print FILENAME, count }' /var/log/app.logКогда использовать awk вместо grep
awk является лучшим выбором, когда:
- Нужно фильтровать по значению столбца (например, «найти строки, где поле 3 больше 500»)
- Нужно выполнять арифметические операции над найденными данными
- Нужно агрегировать результаты (подсчёты, суммы) по файлу
- Файл имеет постоянный разделитель и требуется структурированное извлечение данных
grep остаётся более быстрым для задач чистого сопоставления шаблонов, когда нужно только знать, *существует* ли и *где* находится шаблон.
Сравнение инструментов: grep vs find vs awk
| Критерий | grep | find + grep | awk |
|---|---|---|---|
| Основное назначение | Сопоставление шаблонов в содержимом | Поиск по содержимому с фильтрацией по метаданным | Обработка структурированных данных |
| Рекурсивный поиск | Да (-r / -R) | Да (встроенный) | Нет (требует цикла в оболочке) |
| Фильтрация по метаданным | Нет | Да (имя, размер, дата, владелец) | Нет |
| Поддержка регулярных выражений | BRE, ERE, PCRE | Через grep | ERE |
| Форматирование вывода | Ограниченное | Ограниченное | Полное программируемое управление |
| Производительность на больших деревьях | Быстрая | Медленнее (процесс на файл) | Умеренная |
| Порог вхождения | Низкий | Средний | Высокий |
| Лучший вариант использования | Быстрый поиск по ключевым словам | Производственные аудиты с несколькими критериями | Разбор логов, извлечение данных |
Продвинутые техники для производственных сред
Поиск в сжатых лог-файлах
На серверах, где логи ротируются и сжимаются, используйте zgrep для поиска в файлах .gz без их предварительной распаковки:
zgrep "segfault" /var/log/syslog.*.gzПоиск внутри tar-архивов без извлечения
tar -xOf archive.tar.gz | grep "search_pattern"Объединение grep с sort и uniq для частотного анализа
Найти наиболее распространённые сообщения об ошибках в лог-файле:
grep "ERROR" /var/log/app.log | sort | uniq -c | sort -rn | head -20Исключение бинарных файлов и фокус на исходном коде
grep -r --include="*.py" --include="*.js" --include="*.php" "TODO" /var/www/Мониторинг содержимого в реальном времени с помощью grep
Передайте вывод tail -f в grep для мониторинга живого вывода логов на предмет определённых шаблонов:
tail -f /var/log/nginx/error.log | grep --line-buffered "upstream"Флаг --line-buffered заставляет grep сбрасывать вывод после каждой строки, что необходимо при передаче данных из непрерывного потока.
Варианты использования для аудита безопасности
Поиск файлов по содержимому является основной техникой в усилении безопасности Linux. На Выделенном сервере или VPS эти шаблоны критически важны с операционной точки зрения:
Сканирование на наличие жёстко заданных паролей в файлах веб-приложений:
grep -rniE "(password|passwd|pwd)s*=s*['"][^'"]{3,}" /var/www/ --include="*.php"Найти файлы приватных ключей, доступные для чтения всем:
find / -name "*.pem" -o -name "*.key" | xargs grep -l "PRIVATE KEY"Обнаружение PHP-вебшеллов путём сканирования на наличие распространённых комбинаций функций оболочки:
grep -rPl "evals*(s*(base64_decode|gzinflate|str_rot13)" /var/www/Аудит файлов SSH authorized_keys для всех пользователей:
find /home -name "authorized_keys" -exec grep -H "." {} ;При использовании VPS с cPanel эти аудиты особенно важны, поскольку среды cPanel размещают несколько аккаунтов, и компрометация одного может затронуть другие.
Оптимизация производительности для крупномасштабных поисков
Ограничьте глубину поиска, чтобы избежать ненужного обхода глубоких деревьев директорий:
find /var/www -maxdepth 3 -type f -name "*.php" -exec grep -l "eval(" {} ;Используйте ripgrep для задач, критичных по скорости. Хотя здесь это не рассматривается подробно, rg работает в 3–10 раз быстрее, чем grep на больших кодовых базах благодаря параллелизму и более умной фильтрации файлов. Он доступен в репозиториях большинства дистрибутивов:
apt install ripgrep # Debian/Ubuntu
yum install ripgrep # CentOS/RHELПрофилируйте поиск с помощью time для сравнения различных подходов:
time grep -r "pattern" /large/directory/Избегайте поиска в /proc и /sys — эти виртуальные файловые системы могут вызывать зависания или выдавать бессмысленный вывод:
grep -r --exclude-dir={proc,sys,dev} "pattern" /Выбор правильного подхода: матрица решений
| Сценарий | Рекомендуемая команда | |
|---|---|---|
| Быстрый поиск по ключевому слову в директории | grep -rn "keyword" /path/ | |
| Поиск целого слова без учёта регистра | grep -rniw "keyword" /path/ | |
| Поиск только в определённых типах файлов | grep -r --include="*.conf" "keyword" /path/ | |
| Поиск в недавно изменённых файлах | find /path -mtime -1 -exec grep -l "keyword" {} ; | |
| Эффективный поиск в больших деревьях файлов | `find /path -print0 | xargs -0 grep -l "keyword"` |
| Извлечение структурированных данных из логов | awk '/pattern/ { print $1, $NF }' logfile | |
| Поиск в сжатых логах | zgrep "keyword" /var/log/*.gz | |
| Мониторинг логов в реальном времени | `tail -f /var/log/file.log | grep –line-buffered "pattern"` |
| Аудит безопасности на наличие чувствительных строк | grep -rPl "eval(base64_decode" /var/www/ |
Ключевые технические выводы
- Используйте
grep -rniwв качестве стандартного рекурсивного поиска — он обрабатывает регистр, целые слова и номера строк за один проход. - Всегда используйте
-print0сfindи-0сxargsдля обработки имён файлов, содержащих пробелы или специальные символы. - Используйте
-exec grep ... {} +(знак плюс вместо точки с запятой) для объединения нескольких файлов в один вызовgrepи снижения накладных расходов на процессы. grep -R(заглавная R) следует по символическим ссылкам;grep -r— нет. Знайте, какое поведение требуется в вашей среде.- Устанавливайте
LC_ALL=Cпередgrepв скриптах, чтобы избежать снижения производительности из-за локали и неожиданностей с кодировкой. - Ограничивайте поиск с помощью
--includeи--exclude-dirдля исключения нерелевантных файлов до начала сопоставления шаблонов. - Для многоаккаунтных хостинговых сред, управляемых через Панели управления VPS, планируйте аудиты содержимого как задания cron с использованием этих команд для автоматизации проверок безопасности.
- В средах Общего веб-хостинга права на поиск по содержимому могут быть ограничены хостинг-провайдером — используйте эти команды только в пределах дерева файлов вашего собственного аккаунта.
Часто задаваемые вопросы
Каков самый быстрый способ поиска текста во всех файлах на сервере Linux?
Для скорости на больших деревьях файлов используйте grep -r --include="*.ext" "pattern" /path/ с ограничениями по типу файлов или установите ripgrep (rg "pattern" /path/), который использует многопоточность и обычно работает в 3–10 раз быстрее стандартного grep на больших кодовых базах.
Как искать строку в файлах, исключая определённые директории?
Используйте опцию --exclude-dir команды grep: grep -r --exclude-dir={.git,node_modules,vendor} "pattern" /path/. Для поисков на основе find используйте -not -path "*/dirname/*" перед условием -exec.
В чём разница между grep -r и grep -R?
grep -r выполняет рекурсивный поиск, но не следует по символическим ссылкам. grep -R выполняет тот же рекурсивный поиск и дополнительно следует по символическим ссылкам. Используйте -R только тогда, когда вы уверены, что в целевом дереве директорий нет циклических символических ссылок.
Можно ли искать содержимое внутри сжатых лог-файлов .gz без их распаковки?
Да. Используйте zgrep "pattern" /var/log/file.log.gz для отдельных файлов или zgrep "pattern" /var/log/*.gz для нескольких сжатых файлов. Формат вывода идентичен стандартному grep.
Как искать многострочный шаблон в файлах Linux?
Стандартный grep выполняет сопоставление построчно и не может нативно сопоставлять шаблоны, охватывающие несколько строк. Используйте grep -P с Perl-совместимыми регулярными выражениями и n для символов новой строки, или используйте pcregrep -M "line1nline2" file если доступен pcregrep. Для сложного многострочного извлечения awk с переопределением RS (разделитель записей) часто является наиболее читаемым решением.


