 Українська
Українська English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 на всіх хостингових послугах
на всіх хостингових послугахЯк знайти файл за вмістом у Linux: пояснення grep, find та awk
Пошук файлу за його вмістом у Linux означає сканування даних файлу — не лише імен файлів або метаданих — за допомогою таких інструментів, як grep, find та awk, для пошуку текстових шаблонів, рядків або регулярних виразів в одному або кількох файлах одночасно. Це принципово відрізняється від пошуку за іменем і є правильним підходом, коли ви знаєте, що файл *містить*, але не знаєте, де він знаходиться або як називається.
Для всіх, хто керує середовищем VPS Хостингу, пошук файлів за вмістом є щоденною операційною необхідністю: пошук неправильно налаштованих директив у /etc, аудит лог-файлів на наявність шаблонів помилок або виявлення жорстко закодованих облікових даних у деревах вихідного коду додатків. Команди, розглянуті в цьому посібнику, однаково працюють у всіх основних дистрибутивах Linux — Debian, Ubuntu, CentOS, AlmaLinux та Arch — без необхідності встановлення додаткових пакетів.
Чому пошук за вмістом важливий у середовищах Linux
Пошук за іменем файлу (ls, locate) нічого не говорить про те, що містить файл. У виробничих системах критичні питання майже завжди пов’язані зі вмістом:
- Який конфігураційний файл встановлює
max_connectionsна певне значення? - Який PHP-файл містить застарілий виклик функції, що генерує попередження?
- Який лог-файл зафіксував певну IP-адресу в заданий момент часу?
- Яке визначення завдання cron посилається на шлях до вже видаленого скрипту?
Сучасні файлові менеджери та інструменти пошуку з графічним інтерфейсом не можуть ефективно відповісти на ці питання у великому масштабі. Командний рядок Linux може — і робить це за мілісекунди серед мільйонів файлів при правильному використанні.
Команда grep: основний інструмент для пошуку вмісту
grep (Global Regular Expression Print) — це канонічний інструмент для пошуку вмісту файлів у Linux. Він читає файли рядок за рядком і виводить будь-який рядок, що відповідає заданому шаблону.
Основний синтаксис
grep [OPTIONS] PATTERN [FILE_OR_DIRECTORY]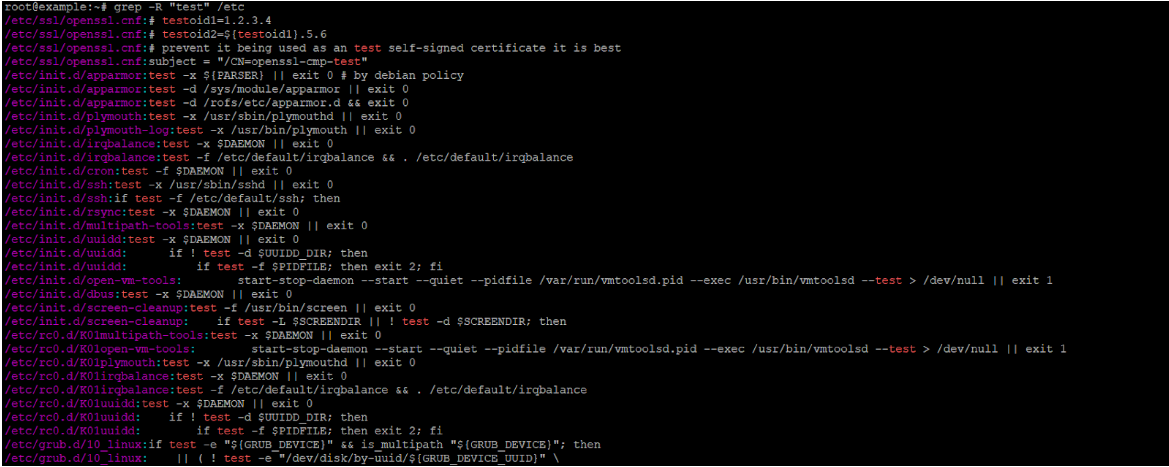
Рекурсивний пошук у директорії
Найпоширенішим реальним використанням є рекурсивний пошук по всьому дереву директорій:
grep -rnw '/path/to/directory/' -e 'search_text'Розбір кожного прапорця:
| Прапорець | Повна назва | Ефект |
|---|---|---|
-r | --recursive | Автоматично переходить у піддиректорії |
-n | --line-number | Додає номер рядка, що збігається, до виводу |
-w | --word-regexp | Збігається лише з цілими словами — test не збігатиметься з testing |
-e | --regexp | Явно оголошує шаблон пошуку; необхідний, коли шаблон починається з дефісу |
-i | --ignore-case | Пошук без урахування регістру (Error збігається з error, ERROR) |
-l | --files-with-matches | Виводить лише імена файлів, а не рядки, що збігаються |
-c | --count | Виводить лише кількість рядків, що збігаються, для кожного файлу |
-v | --invert-match | Повертає рядки, які НЕ відповідають шаблону |
-A N | --after-context=N | Показує N рядків після кожного збігу для контексту |
-B N | --before-context=N | Показує N рядків перед кожним збігом для контексту |
--include | N/A | Обмежує пошук файлами, що відповідають шаблону glob |
--exclude | N/A | Пропускає файли, що відповідають шаблону glob |
Практичні приклади grep
Пошук рядка "test1" всередині /usr/games та всіх піддиректорій:
grep -r "test1" /usr/gamesЗнайти всі файли в /etc, що містять слово "network" (ціле слово, без урахування регістру), з відображенням номерів рядків:
grep -rniw "network" /etcВивести лише імена файлів (без рядків, що збігаються) PHP-файлів, що містять eval(:
grep -rl "eval(" /var/www/html --include="*.php"Пошук шаблону з відображенням 3 рядків контексту до і після кожного збігу:
grep -rn -A 3 -B 3 "FATAL" /var/log/Підрахувати, скільки разів "PermitRootLogin" зустрічається у всіх конфігураційних файлах SSH:
grep -rc "PermitRootLogin" /etc/ssh/Знайти рядки, що НЕ містять "localhost" у файлі hosts:
grep -v "localhost" /etc/hostsgrep з регулярними виразами
grep підтримує три рушії регулярних виразів:
- BRE (Basic Regular Expressions) — режим за замовчуванням
- ERE (Extended Regular Expressions) — активується за допомогою
-Eабоegrep - PCRE (Perl-Compatible Regular Expressions) — активується за допомогою
-P
# Match lines containing an IPv4 address pattern (ERE)
grep -rE '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/nginx/access.log
# Match lines with email addresses (PCRE)
grep -rP '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}' /var/www/html/Критичні граничні випадки та підводні камені grep
Бінарні файли: За замовчуванням grep виводить Binary file X matches для бінарних файлів і пропускає їх вміст. Використовуйте -a (--text), щоб змусити grep обробляти бінарні файли як текст — корисно при пошуку в скомпільованих конфігах або дампах баз даних. Використовуйте з обережністю на великих бінарних файлах.
Символічні посилання: -r не слідує символічним посиланням. Використовуйте -R (велика R) для рекурсивного слідування символічним посиланням. Майте на увазі, що це може створювати нескінченні цикли при наявності кільцевих символічних посилань.
Продуктивність на великих деревах: grep за замовчуванням є однопотоковим. Для масивних кодових баз (мільйони файлів) розгляньте ripgrep (rg) або ag (The Silver Searcher), які є багатопотоковими та автоматично враховують шаблони .gitignore.
Нульові байти в іменах файлів: Передавайте вивід find через -print0 та використовуйте grep --null або xargs -0 для безпечної обробки імен файлів, що містять пробіли або спеціальні символи.
Проблеми з кодуванням: grep працює з байтами, а не символами. Якщо файли використовують UTF-16 або інші кодування, результати можуть бути ненадійними. Встановіть LANG=C або LC_ALL=C перед командою, щоб примусово використовувати побайтове зіставлення:
LC_ALL=C grep -r "pattern" /path/Команда find: поєднання метаданих файлів і пошуку вмісту
Тоді як grep шукає *всередині* файлів, find знаходить файли на основі їх метаданих — імені, типу, розміру, прав доступу, часу модифікації — і може виконувати довільні команди для кожного результату. Поєднання find з grep дає точний багатокритеріальний пошук вмісту.
Основний синтаксис
find /starting/path [CRITERIA] [ACTION]Пошук вмісту за допомогою find + grep
find /path/to/directory/ -type f -exec grep -l 'search_text' {} ;Анатомія цієї команди:
| Компонент | Значення |
|---|---|
/path/to/directory/ | Коренева директорія для пошуку |
-type f | Обмежує результати лише звичайними файлами (виключає директорії, сокети, пристрої) |
-exec ... {} ; | Виконує вказану команду для кожного знайденого файлу; {} замінюється іменем файлу |
grep -l | Виводить лише ім’я файлу при знаходженні збігу, а не рядок, що збігається |
Поєднання критеріїв find для точності
Справжня потужність find полягає в накладанні кількох критеріїв перед виконанням grep, що значно скорочує кількість файлів, які потрібно сканувати:
Пошук лише у файлах .conf, змінених за останні 7 днів:
find /etc -type f -name "*.conf" -mtime -7 -exec grep -l "timeout" {} ;Пошук лише у файлах розміром більше 1MB:
find /var/log -type f -size +1M -exec grep -c "ERROR" {} ;Пошук у файлах, що належать певному користувачу:
find /home -type f -user john -exec grep -l "password" {} ;Пошук файлів з певними правами доступу (доступних для запису всім):
find /var/www -type f -perm -o+w -exec grep -l "eval(" {} ;Виключення директорії з пошуку:
find /var/www -type f -not -path "*/node_modules/*" -exec grep -l "API_KEY" {} ;Використання find з xargs для кращої продуктивності
Синтаксис -exec ... ; породжує новий процес для кожного знайденого файлу. У директоріях з тисячами файлів це помітно повільніше. Використання xargs групує кілька імен файлів в один виклик grep:
find /path/ -type f -name "*.log" -print0 | xargs -0 grep -l "connection refused"Прапорці -print0 та -0 використовують нульові символи як роздільники замість символів нового рядка, що правильно обробляє імена файлів з пробілами.
Команда awk: структурований пошук і вилучення вмісту
awk — це повноцінна мова обробки тексту, а не просто інструмент пошуку. Вона відмінно підходить, коли потрібно шукати шаблони у структурованих файлах — CSV-даних, лог-файлах з фіксованими стовпцями, конфігураційних файлах — і одночасно вилучати, перетворювати або обчислювати дані з знайдених збігів.
Основний синтаксис
awk '/pattern/ { action }' fileПрактичні приклади awk для пошуку вмісту файлів
Вивести всі рядки у файлі, що містять слово "error":
awk '/error/' /var/log/syslogПошук шаблону та виведення лише певних полів (стовпець 1 і стовпець 5):
awk '/FAILED/ { print $1, $5 }' /var/log/auth.logПошук у кількох файлах з виведенням імені файлу та рядків, що збігаються:
awk '/search_term/ { print FILENAME": "$0 }' /etc/nginx/*.confПошук без урахування регістру в awk:
awk 'tolower($0) ~ /timeout/' /etc/mysql/my.cnfПідрахунок входжень шаблону для кожного файлу:
awk '/ERROR/ { count++ } END { print FILENAME, count }' /var/log/app.logКоли використовувати awk замість grep
awk є кращим вибором, коли:
- Потрібно фільтрувати за значенням стовпця (наприклад, "знайти рядки, де поле 3 більше 500")
- Потрібно виконувати арифметичні операції над знайденими даними
- Потрібно агрегувати результати (підрахунки, суми) по файлу
- Файл має постійний роздільник і потрібне структуроване вилучення даних
grep залишається швидшим для завдань чистого пошуку шаблонів, де потрібно лише знати *чи* і *де* існує шаблон.
Порівняння інструментів: grep vs find vs awk
| Критерій | grep | find + grep | awk |
|---|---|---|---|
| Основне призначення | Пошук шаблонів у вмісті | Пошук вмісту з фільтрацією за метаданими | Обробка структурованих даних |
| Рекурсивний пошук | Так (-r / -R) | Так (вбудований) | Ні (потребує циклу оболонки) |
| Фільтрація за метаданими | Ні | Так (ім’я, розмір, дата, власник) | Ні |
| Підтримка регулярних виразів | BRE, ERE, PCRE | Через grep | ERE |
| Форматування виводу | Обмежене | Обмежене | Повне програмоване керування |
| Продуктивність на великих деревах | Швидка | Повільніша (окремий процес для кожного файлу) | Помірна |
| Крива навчання | Низька | Середня | Висока |
| Найкращий варіант використання | Швидкий пошук за ключовим словом | Багатокритеріальні виробничі аудити | Аналіз логів, вилучення даних |
Розширені техніки для виробничих середовищ
Пошук у стиснутих лог-файлах
На серверах, де логи ротуються та стискаються, використовуйте zgrep для пошуку у файлах .gz без їх попереднього розпакування:
zgrep "segfault" /var/log/syslog.*.gzПошук всередині tar-архівів без розпакування
tar -xOf archive.tar.gz | grep "search_pattern"Поєднання grep з sort та uniq для частотного аналізу
Знайти найпоширеніші повідомлення про помилки у лог-файлі:
grep "ERROR" /var/log/app.log | sort | uniq -c | sort -rn | head -20Виключення бінарних файлів і фокус на вихідному коді
grep -r --include="*.py" --include="*.js" --include="*.php" "TODO" /var/www/Моніторинг вмісту в реальному часі за допомогою grep
Передавайте вивід tail -f до grep для моніторингу живого виводу логів на наявність певних шаблонів:
tail -f /var/log/nginx/error.log | grep --line-buffered "upstream"Прапорець --line-buffered змушує grep скидати вивід після кожного рядка, що є необхідним при передачі з безперервного потоку.
Варіанти використання для аудиту безпеки
Пошук файлів за вмістом є основною технікою у зміцненні безпеки Linux. На Виділеному сервері або VPS ці шаблони є критично важливими з операційної точки зору:
Сканування на наявність жорстко закодованих паролів у файлах веб-додатків:
grep -rniE "(password|passwd|pwd)s*=s*['"][^'"]{3,}" /var/www/ --include="*.php"Знайти файли приватних ключів, доступні для читання всім:
find / -name "*.pem" -o -name "*.key" | xargs grep -l "PRIVATE KEY"Виявлення PHP-вебшелів шляхом сканування на наявність поширених комбінацій функцій оболонки:
grep -rPl "evals*(s*(base64_decode|gzinflate|str_rot13)" /var/www/Аудит файлів SSH authorized_keys для всіх користувачів:
find /home -name "authorized_keys" -exec grep -H "." {} ;При використанні VPS з cPanel ці аудити є особливо важливими, оскільки середовища cPanel обслуговують кілька облікових записів і компрометація одного може вплинути на інші.
Оптимізація продуктивності для великомасштабних пошуків
Обмежте глибину пошуку, щоб уникнути непотрібного обходу глибоких дерев директорій:
find /var/www -maxdepth 3 -type f -name "*.php" -exec grep -l "eval(" {} ;Використовуйте ripgrep для критичних за швидкістю завдань. Хоча тут це не розглядається детально, rg у 3–10 разів швидший за grep на великих кодових базах завдяки паралелізму та розумнішій фільтрації файлів. Він доступний у репозиторіях більшості дистрибутивів:
apt install ripgrep # Debian/Ubuntu
yum install ripgrep # CentOS/RHELПрофілюйте пошук за допомогою time для порівняльного тестування різних підходів:
time grep -r "pattern" /large/directory/Уникайте пошуку в /proc та /sys — ці віртуальні файлові системи можуть спричиняти зависання або виводити безглузді результати:
grep -r --exclude-dir={proc,sys,dev} "pattern" /Вибір правильного підходу: матриця рішень
| Сценарій | Рекомендована команда | |
|---|---|---|
| Швидкий пошук за ключовим словом у директорії | grep -rn "keyword" /path/ | |
| Пошук цілого слова без урахування регістру | grep -rniw "keyword" /path/ | |
| Пошук лише у певних типах файлів | grep -r --include="*.conf" "keyword" /path/ | |
| Пошук у нещодавно змінених файлах | find /path -mtime -1 -exec grep -l "keyword" {} ; | |
| Ефективний пошук у великих деревах файлів | `find /path -print0 | xargs -0 grep -l "keyword"` |
| Вилучення структурованих даних з логів | awk '/pattern/ { print $1, $NF }' logfile | |
| Пошук у стиснутих логах | zgrep "keyword" /var/log/*.gz | |
| Моніторинг логів у реальному часі | `tail -f /var/log/file.log | grep –line-buffered "pattern"` |
| Аудит безпеки на наявність чутливих рядків | grep -rPl "eval(base64_decode" /var/www/ |
Ключові технічні висновки
- Використовуйте
grep -rniwяк стандартний рекурсивний пошук — він обробляє регістр, цілі слова та номери рядків за один прохід. - Завжди використовуйте
-print0зfindта-0зxargsдля обробки імен файлів, що містять пробіли або спеціальні символи. - Використовуйте
-exec grep ... {} +(знак плюс замість крапки з комою) для групування кількох файлів в один викликgrepта зменшення накладних витрат на процеси. grep -R(велика R) слідує символічним посиланням;grep -r— ні; знайте, яка поведінка потрібна у вашому середовищі.- Встановлюйте
LC_ALL=Cпередgrepу скриптах, щоб уникнути штрафів за продуктивність, пов’язаних з локаллю, та несподіванок з кодуванням. - Обмежуйте пошук за допомогою
--includeта--exclude-dirдля виключення нерелевантних файлів до початку пошуку шаблонів. - Для багатоакаунтних хостингових середовищ, що керуються через Панелі керування VPS, плануйте аудити вмісту як завдання cron за допомогою цих команд для автоматизації перевірок безпеки.
- У середовищах Спільного веб-хостингу права на пошук вмісту можуть бути обмежені хостинг-провайдером — використовуйте ці команди лише в межах дерева файлів власного облікового запису.
Часті запитання
Який найшвидший спосіб пошуку тексту у всіх файлах на сервері Linux?
Для швидкості на великих деревах файлів використовуйте grep -r --include="*.ext" "pattern" /path/ з обмеженнями типів файлів або встановіть ripgrep (rg "pattern" /path/), який використовує багатопоточність і зазвичай у 3–10 разів швидший за стандартний grep на великих кодових базах.
Як шукати рядок у файлах, виключаючи певні директорії?
Використовуйте опцію --exclude-dir команди grep: grep -r --exclude-dir={.git,node_modules,vendor} "pattern" /path/. Для пошуків на основі find використовуйте -not -path "*/dirname/*" перед умовою -exec.
У чому різниця між grep -r та grep -R?
grep -r виконує рекурсивний пошук, але не слідує символічним посиланням. grep -R виконує той самий рекурсивний пошук і додатково слідує символічним посиланням. Використовуйте -R лише тоді, коли ви впевнені, що в цільовому дереві директорій немає кільцевих символічних посилань.
Чи можна шукати вміст у стиснутих лог-файлах .gz без їх розпакування?
Так. Використовуйте zgrep "pattern" /var/log/file.log.gz для окремих файлів або zgrep "pattern" /var/log/*.gz для кількох стиснутих файлів. Формат виводу ідентичний стандартному grep.
Як шукати багаторядковий шаблон у файлах Linux?
Стандартний grep зіставляє рядок за рядком і не може нативно зіставляти шаблони, що охоплюють кілька рядків. Використовуйте grep -P з Perl-сумісними регулярними виразами та n для символів нового рядка, або використовуйте pcregrep -M "line1nline2" file якщо pcregrep доступний. Для складного багаторядкового вилучення awk з перевизначенням RS (роздільник записів) часто є найбільш читабельним рішенням.


