 Polski
Polski English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 na wszystkich usługach hostingowych
na wszystkich usługach hostingowychJak znaleźć plik według zawartości w Linux: grep, find i awk wyjaśnione
Wyszukiwanie pliku według jego zawartości w Linux oznacza skanowanie danych pliku — nie tylko nazw plików ani metadanych — przy użyciu narzędzi takich jak grep, find i awk, aby dopasować wzorce tekstowe, ciągi znaków lub wyrażenia regularne w jednym lub wielu plikach jednocześnie. Różni się to zasadniczo od wyszukiwania opartego na nazwach i jest właściwym podejściem, gdy wiesz, co plik *zawiera*, ale nie wiesz, gdzie się znajduje ani jak się nazywa.
Dla każdego zarządzającego środowiskiem VPS Hosting, wyszukiwanie plików według zawartości jest codzienną koniecznością operacyjną: lokalizowanie błędnie skonfigurowanych dyrektyw w /etc, audytowanie plików dziennika pod kątem wzorców błędów lub wyszukiwanie zakodowanych na stałe poświadczeń w drzewach źródłowych aplikacji. Polecenia omówione w tym przewodniku działają identycznie we wszystkich głównych dystrybucjach Linux — Debian, Ubuntu, CentOS, AlmaLinux i Arch — bez konieczności instalowania dodatkowych pakietów.
Dlaczego wyszukiwanie oparte na zawartości ma znaczenie w środowiskach Linux
Wyszukiwanie oparte na nazwach plików (ls, locate) nie mówi nic o tym, co plik zawiera. W systemach produkcyjnych kluczowe pytania są prawie zawsze związane z zawartością:
- Który plik konfiguracyjny ustawia
max_connectionsna określoną wartość? - Który plik PHP zawiera przestarzałe wywołanie funkcji, które generuje ostrzeżenia?
- Który plik dziennika zarejestrował określony adres IP w danym znaczniku czasu?
- Która definicja zadania cron odwołuje się do usuniętej ścieżki skryptu?
Nowoczesne menedżery plików i graficzne narzędzia wyszukiwania nie mogą efektywnie odpowiedzieć na te pytania w dużej skali. Wiersz poleceń Linux może — i robi to w milisekundach na milionach plików, gdy jest używany prawidłowo.
Polecenie grep: podstawowe narzędzie do wyszukiwania zawartości
grep (Global Regular Expression Print) jest kanonicznym narzędziem do wyszukiwania zawartości plików w Linux. Odczytuje pliki wiersz po wierszu i wyświetla każdy wiersz pasujący do podanego wzorca.
Podstawowa składnia
grep [OPTIONS] PATTERN [FILE_OR_DIRECTORY]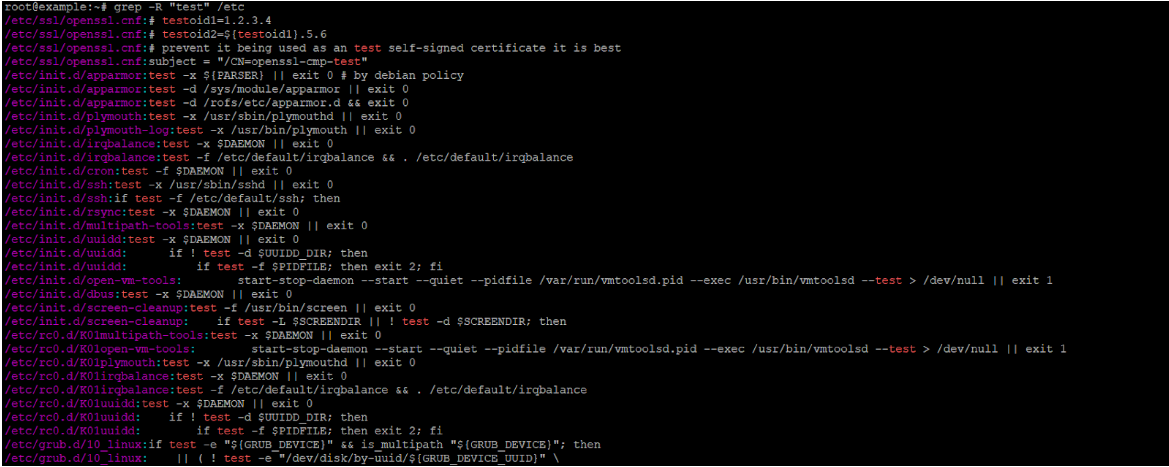
Rekurencyjne wyszukiwanie w katalogu
Najczęstszym zastosowaniem w praktyce jest rekurencyjne wyszukiwanie w całym drzewie katalogów:
grep -rnw '/path/to/directory/' -e 'search_text'Objaśnienie każdej flagi:
| Flaga | Pełna nazwa | Działanie |
|---|---|---|
-r | --recursive | Automatycznie schodzi do podkatalogów |
-n | --line-number | Poprzedza numer pasującego wiersza w wynikach |
-w | --word-regexp | Dopasowuje tylko całe słowa — test nie dopasuje testing |
-e | --regexp | Jawnie deklaruje wzorzec wyszukiwania; wymagane, gdy wzorzec zaczyna się od myślnika |
-i | --ignore-case | Dopasowywanie bez rozróżniania wielkości liter (Error dopasowuje error, ERROR) |
-l | --files-with-matches | Wyświetla tylko nazwy plików, nie pasujące wiersze |
-c | --count | Wyświetla tylko liczbę pasujących wierszy na plik |
-v | --invert-match | Zwraca wiersze, które NIE pasują do wzorca |
-A N | --after-context=N | Pokazuje N wierszy po każdym dopasowaniu dla kontekstu |
-B N | --before-context=N | Pokazuje N wierszy przed każdym dopasowaniem dla kontekstu |
--include | N/A | Ogranicza wyszukiwanie do plików pasujących do wzorca glob |
--exclude | N/A | Pomija pliki pasujące do wzorca glob |
Praktyczne przykłady grep
Wyszukaj ciąg „test1″ w /usr/games i wszystkich podkatalogach:
grep -r "test1" /usr/gamesZnajdź wszystkie pliki w /etc zawierające słowo „network” (całe słowo, bez rozróżniania wielkości liter), pokazując numery wierszy:
grep -rniw "network" /etcWyświetl tylko nazwy plików (nie pasujące wiersze) plików PHP zawierających eval(:
grep -rl "eval(" /var/www/html --include="*.php"Wyszukaj wzorzec i wyświetl 3 wiersze kontekstu przed i po każdym dopasowaniu:
grep -rn -A 3 -B 3 "FATAL" /var/log/Policz, ile razy „PermitRootLogin” pojawia się we wszystkich plikach konfiguracyjnych SSH:
grep -rc "PermitRootLogin" /etc/ssh/Znajdź wiersze, które NIE zawierają „localhost” w pliku hosts:
grep -v "localhost" /etc/hostsgrep z wyrażeniami regularnymi
grep obsługuje trzy silniki regex:
- BRE (Basic Regular Expressions) — tryb domyślny
- ERE (Extended Regular Expressions) — aktywowany przez
-Elubegrep - PCRE (Perl-Compatible Regular Expressions) — aktywowany przez
-P
# Match lines containing an IPv4 address pattern (ERE)
grep -rE '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/nginx/access.log
# Match lines with email addresses (PCRE)
grep -rP '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}' /var/www/html/Krytyczne przypadki brzegowe i pułapki związane z grep
Pliki binarne: Domyślnie grep wyświetli Binary file X matches dla plików binarnych i pominie ich zawartość. Użyj -a (--text), aby wymusić traktowanie plików binarnych jako tekstu — przydatne podczas przeszukiwania skompilowanych konfiguracji lub zrzutów bazy danych. Używaj ostrożnie na dużych plikach binarnych.
Dowiązania symboliczne: -r nie podąża za dowiązaniami symbolicznymi. Użyj -R (duże R), aby rekurencyjnie podążać za dowiązaniami symbolicznymi. Pamiętaj, że może to powodować nieskończone pętle, jeśli istnieją okrężne dowiązania symboliczne.
Wydajność na dużych drzewach: grep jest domyślnie jednowątkowy. W przypadku ogromnych baz kodu (miliony plików) rozważ użycie ripgrep (rg) lub ag (The Silver Searcher), które są wielowątkowe i automatycznie respektują wzorce .gitignore.
Znaki null w nazwach plików: Przekieruj wyniki find przez -print0 i użyj grep --null lub xargs -0, aby bezpiecznie obsługiwać nazwy plików zawierające spacje lub znaki specjalne.
Problemy z kodowaniem: grep operuje na bajtach, nie na znakach. Jeśli pliki używają UTF-16 lub innych kodowań, wyniki mogą być niewiarygodne. Ustaw LANG=C lub LC_ALL=C przed poleceniem, aby wymusić dopasowywanie na poziomie bajtów:
LC_ALL=C grep -r "pattern" /path/Polecenie find: łączenie metadanych pliku z wyszukiwaniem zawartości
Podczas gdy grep przeszukuje pliki *od wewnątrz*, find lokalizuje pliki na podstawie ich metadanych — nazwy, typu, rozmiaru, uprawnień, czasu modyfikacji — i może następnie wykonywać dowolne polecenia na każdym wyniku. Połączenie find z grep daje precyzyjne wyszukiwanie zawartości według wielu kryteriów.
Podstawowa składnia
find /starting/path [CRITERIA] [ACTION]Wyszukiwanie zawartości przy użyciu find + grep
find /path/to/directory/ -type f -exec grep -l 'search_text' {} ;Anatomia tego polecenia:
| Składnik | Znaczenie |
|---|---|
/path/to/directory/ | Katalog główny wyszukiwania |
-type f | Ogranicza wyniki tylko do zwykłych plików (wyklucza katalogi, gniazda, urządzenia) |
-exec ... {} ; | Wykonuje określone polecenie raz dla każdego dopasowanego pliku; {} jest zastępowane nazwą pliku |
grep -l | Wyświetla tylko nazwę pliku, jeśli znaleziono dopasowanie, nie pasujący wiersz |
Łączenie kryteriów find dla precyzji
Prawdziwa moc find polega na nakładaniu wielu kryteriów przed wykonaniem grep, co drastycznie zmniejsza liczbę plików wymagających skanowania:
Przeszukaj tylko pliki .conf zmodyfikowane w ciągu ostatnich 7 dni:
find /etc -type f -name "*.conf" -mtime -7 -exec grep -l "timeout" {} ;Przeszukaj tylko pliki większe niż 1MB:
find /var/log -type f -size +1M -exec grep -c "ERROR" {} ;Przeszukaj pliki należące do określonego użytkownika:
find /home -type f -user john -exec grep -l "password" {} ;Przeszukaj pliki z określonymi uprawnieniami (dostępne do zapisu dla wszystkich):
find /var/www -type f -perm -o+w -exec grep -l "eval(" {} ;Wyklucz katalog z wyszukiwania:
find /var/www -type f -not -path "*/node_modules/*" -exec grep -l "API_KEY" {} ;Używanie find z xargs dla lepszej wydajności
Składnia -exec ... ; tworzy nowy proces dla każdego znalezionego pliku. W katalogach z tysiącami plików jest to mierzalnie wolniejsze. Użycie xargs grupuje wiele nazw plików w jedno wywołanie grep:
find /path/ -type f -name "*.log" -print0 | xargs -0 grep -l "connection refused"Flagi -print0 i -0 używają znaków null jako separatorów zamiast nowych wierszy, poprawnie obsługując nazwy plików ze spacjami.
Polecenie awk: strukturalne wyszukiwanie i ekstrakcja zawartości
awk jest pełnym językiem przetwarzania tekstu, a nie tylko narzędziem wyszukiwania. Sprawdza się doskonale, gdy trzeba wyszukiwać wzorce w plikach strukturalnych — danych CSV, plikach dziennika ze stałymi kolumnami, plikach konfiguracyjnych — i jednocześnie ekstrahować, przekształcać lub obliczać na podstawie dopasowanych danych.
Podstawowa składnia
awk '/pattern/ { action }' filePraktyczne przykłady awk do wyszukiwania zawartości plików
Wyświetl wszystkie wiersze w pliku zawierające słowo „error”:
awk '/error/' /var/log/syslogWyszukaj wzorzec i wyświetl tylko określone pola (kolumna 1 i kolumna 5):
awk '/FAILED/ { print $1, $5 }' /var/log/auth.logPrzeszukaj wiele plików i wyświetl nazwę pliku z pasującymi wierszami:
awk '/search_term/ { print FILENAME": "$0 }' /etc/nginx/*.confWyszukiwanie bez rozróżniania wielkości liter w awk:
awk 'tolower($0) ~ /timeout/' /etc/mysql/my.cnfZlicz wystąpienia wzorca na plik:
awk '/ERROR/ { count++ } END { print FILENAME, count }' /var/log/app.logKiedy używać awk zamiast grep
awk jest lepszym wyborem, gdy:
- Musisz filtrować według wartości kolumny (np. „znajdź wiersze, w których pole 3 jest większe niż 500″)
- Musisz wykonywać operacje arytmetyczne na dopasowanych danych
- Musisz agregować wyniki (liczby, sumy) w pliku
- Plik ma spójny separator i potrzebujesz strukturalnej ekstrakcji
grep pozostaje szybszy w przypadku zadań czystego dopasowywania wzorców, gdy potrzebujesz tylko wiedzieć *czy* i *gdzie* wzorzec istnieje.
Porównanie narzędzi: grep vs find vs awk
| Kryterium | grep | find + grep | awk |
|---|---|---|---|
| Główny cel | Dopasowywanie wzorców zawartości | Wyszukiwanie zawartości filtrowane według metadanych | Przetwarzanie danych strukturalnych |
| Wyszukiwanie rekurencyjne | Tak (-r / -R) | Tak (natywne) | Nie (wymaga pętli powłoki) |
| Filtrowanie metadanych | Nie | Tak (nazwa, rozmiar, data, właściciel) | Nie |
| Obsługa wyrażeń regularnych | BRE, ERE, PCRE | Przez grep | ERE |
| Formatowanie wyników | Ograniczone | Ograniczone | Pełna programowalna kontrola |
| Wydajność na dużych drzewach | Szybka | Wolniejsza (jeden proces na plik) | Umiarkowana |
| Krzywa uczenia się | Niska | Średnia | Wysoka |
| Najlepszy przypadek użycia | Szybkie wyszukiwanie słów kluczowych | Audyty produkcyjne według wielu kryteriów | Parsowanie logów, ekstrakcja danych |
Zaawansowane techniki dla środowisk produkcyjnych
Przeszukiwanie skompresowanych plików dziennika
Na serwerach, gdzie logi są rotowane i kompresowane, użyj zgrep, aby przeszukiwać pliki .gz bez ich wcześniejszego dekompresowania:
zgrep "segfault" /var/log/syslog.*.gzPrzeszukiwanie archiwów tar bez ich rozpakowywania
tar -xOf archive.tar.gz | grep "search_pattern"Łączenie grep z sort i uniq do analizy częstotliwości
Znajdź najczęstsze komunikaty o błędach w pliku dziennika:
grep "ERROR" /var/log/app.log | sort | uniq -c | sort -rn | head -20Wykluczanie plików binarnych i skupianie się na kodzie źródłowym
grep -r --include="*.py" --include="*.js" --include="*.php" "TODO" /var/www/Monitorowanie zawartości w czasie rzeczywistym za pomocą grep
Przekieruj tail -f do grep, aby monitorować na żywo dane wyjściowe dziennika pod kątem określonych wzorców:
tail -f /var/log/nginx/error.log | grep --line-buffered "upstream"Flaga --line-buffered wymusza na grep opróżnianie bufora wyjściowego po każdym wierszu, co jest niezbędne przy przekierowaniu z ciągłego strumienia.
Przypadki użycia w audycie bezpieczeństwa
Wyszukiwanie plików według zawartości jest podstawową techniką w utwardzaniu bezpieczeństwa Linux. Na Dedicated Server lub VPS, te wzorce są krytyczne operacyjnie:
Skanuj w poszukiwaniu zakodowanych na stałe haseł w plikach aplikacji webowych:
grep -rniE "(password|passwd|pwd)s*=s*['"][^'"]{3,}" /var/www/ --include="*.php"Znajdź pliki kluczy prywatnych dostępne do odczytu dla wszystkich:
find / -name "*.pem" -o -name "*.key" | xargs grep -l "PRIVATE KEY"Wykryj webshelle PHP, skanując w poszukiwaniu typowych kombinacji funkcji powłoki:
grep -rPl "evals*(s*(base64_decode|gzinflate|str_rot13)" /var/www/Przeprowadź audyt plików SSH authorized_keys dla wszystkich użytkowników:
find /home -name "authorized_keys" -exec grep -H "." {} ;Podczas korzystania z VPS z cPanel, te audyty są szczególnie ważne, ponieważ środowiska cPanel obsługują wiele kont i kompromitacja jednego może wpłynąć na inne.
Optymalizacja wydajności dla wyszukiwań na dużą skalę
Ogranicz głębokość wyszukiwania, aby uniknąć niepotrzebnego przechodzenia przez głębokie drzewa katalogów:
find /var/www -maxdepth 3 -type f -name "*.php" -exec grep -l "eval(" {} ;Używaj ripgrep do zadań krytycznych pod względem szybkości. Choć nie jest tu szczegółowo omówiony, rg jest 3–10x szybszy niż grep na dużych bazach kodu dzięki równoległości i inteligentniejszemu filtrowaniu plików. Jest dostępny w repozytoriach większości dystrybucji:
apt install ripgrep # Debian/Ubuntu
yum install ripgrep # CentOS/RHELProfiluj wyszukiwanie za pomocą time, aby porównać różne podejścia:
time grep -r "pattern" /large/directory/Unikaj przeszukiwania /proc i /sys — te wirtualne systemy plików mogą powodować zawieszenia lub generować bezużyteczne wyniki:
grep -r --exclude-dir={proc,sys,dev} "pattern" /Wybór właściwego podejścia: macierz decyzyjna
| Scenariusz | Zalecane polecenie | |
|---|---|---|
| Szybkie wyszukiwanie słów kluczowych w katalogu | grep -rn "keyword" /path/ | |
| Wyszukiwanie całych słów bez rozróżniania wielkości liter | grep -rniw "keyword" /path/ | |
| Wyszukiwanie tylko określonych typów plików | grep -r --include="*.conf" "keyword" /path/ | |
| Wyszukiwanie plików zmodyfikowanych niedawno | find /path -mtime -1 -exec grep -l "keyword" {} ; | |
| Efektywne przeszukiwanie dużych drzew plików | `find /path -print0 | xargs -0 grep -l "keyword"` |
| Ekstrakcja danych strukturalnych z logów | awk '/pattern/ { print $1, $NF }' logfile | |
| Przeszukiwanie skompresowanych logów | zgrep "keyword" /var/log/*.gz | |
| Monitorowanie logów w czasie rzeczywistym | `tail -f /var/log/file.log | grep –line-buffered "pattern"` |
| Audyt bezpieczeństwa pod kątem wrażliwych ciągów | grep -rPl "eval(base64_decode" /var/www/ |
Kluczowe wnioski techniczne
- Używaj
grep -rniwjako domyślnego wyszukiwania rekurencyjnego — obsługuje wielkość liter, całe słowa i numery wierszy w jednym przebiegu. - Zawsze używaj
-print0zfindi-0zxargs, aby obsługiwać nazwy plików zawierające spacje lub znaki specjalne. - Używaj
-exec grep ... {} +(znak plus zamiast średnika), aby grupować wiele plików na jedno wywołaniegrepi zmniejszyć narzut procesów. grep -R(duże R) podąża za dowiązaniami symbolicznymi;grep -rnie — wiedz, które zachowanie jest wymagane w Twoim środowisku.- Ustaw
LC_ALL=Cprzedgrepw skryptach, aby uniknąć problemów z wydajnością związanych z ustawieniami regionalnymi i niespodzianek z kodowaniem. - Ogranicz wyszukiwania używając
--includei--exclude-dir, aby wyeliminować nieistotne pliki przed rozpoczęciem dopasowywania wzorców. - W środowiskach hostingowych z wieloma kontami zarządzanymi przez VPS Control Panels, zaplanuj audyty zawartości jako zadania cron używając tych poleceń, aby zautomatyzować kontrole bezpieczeństwa.
- W środowiskach Shared Web Hosting uprawnienia do wyszukiwania zawartości mogą być ograniczone przez dostawcę hostingu — używaj tych poleceń tylko w drzewie plików własnego konta.
Często zadawane pytania
Jaki jest najszybszy sposób wyszukiwania tekstu we wszystkich plikach na serwerze Linux?
Dla szybkości na dużych drzewach plików użyj grep -r --include="*.ext" "pattern" /path/ z ograniczeniami typów plików lub zainstaluj ripgrep (rg "pattern" /path/), który używa wielowątkowości i jest zazwyczaj 3–10x szybszy niż standardowy grep na dużych bazach kodu.
Jak wyszukiwać ciąg w plikach, wykluczając określone katalogi?
Użyj opcji --exclude-dir w grep: grep -r --exclude-dir={.git,node_modules,vendor} "pattern" /path/. W przypadku wyszukiwań opartych na find użyj -not -path "*/dirname/*" przed klauzulą -exec.
Jaka jest różnica między grep -r a grep -R?
grep -r wykonuje wyszukiwanie rekurencyjne, ale nie podąża za dowiązaniami symbolicznymi. grep -R wykonuje to samo wyszukiwanie rekurencyjne i dodatkowo podąża za dowiązaniami symbolicznymi. Używaj -R tylko wtedy, gdy masz pewność, że w docelowym drzewie katalogów nie istnieją okrężne dowiązania symboliczne.
Czy mogę przeszukiwać zawartość skompresowanych plików dziennika .gz bez ich dekompresowania?
Tak. Użyj zgrep "pattern" /var/log/file.log.gz dla pojedynczych plików lub zgrep "pattern" /var/log/*.gz dla wielu skompresowanych plików. Format wyników jest identyczny jak w standardowym grep.
Jak wyszukiwać wielowierszowy wzorzec w plikach Linux?
Standardowy grep dopasowuje wiersz po wierszu i nie może natywnie dopasowywać wzorców obejmujących wiele wierszy. Użyj grep -P z wyrażeniami regularnymi zgodnymi z Perlem i n dla nowych wierszy, lub użyj pcregrep -M "line1nline2" file jeśli pcregrep jest dostępny. W przypadku złożonej ekstrakcji wielowierszowej, awk z przedefiniowaniem RS (separator rekordów) jest często najbardziej czytelnym rozwiązaniem.


