 Deutsch
Deutsch English
English  Русский
Русский  Română
Română  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 bei allen Hosting-Diensten
bei allen Hosting-DienstenSo finden Sie eine Datei nach Inhalt in Linux: grep, find und awk erklärt
Eine Datei nach ihrem Inhalt in Linux zu suchen bedeutet, Dateidaten zu durchsuchen — nicht nur Dateinamen oder Metadaten — mithilfe von Tools wie grep, find und awk, um Textmuster, Zeichenketten oder reguläre Ausdrücke über eine oder mehrere Dateien gleichzeitig abzugleichen. Dies unterscheidet sich grundlegend von namensbasierten Suchen und ist der richtige Ansatz, wenn Sie wissen, was eine Datei *enthält*, aber nicht, wo sie sich befindet oder wie sie heißt.
Für alle, die eine VPS Hosting-Umgebung verwalten, ist die inhaltsbasierte Dateisuche eine tägliche betriebliche Notwendigkeit: das Auffinden falsch konfigurierter Direktiven in /etc, die Überprüfung von Log-Dateien auf Fehlermuster oder die Suche nach fest codierten Anmeldedaten in Anwendungsquellverzeichnissen. Die in diesem Leitfaden behandelten Befehle funktionieren identisch auf allen wichtigen Linux-Distributionen — Debian, Ubuntu, CentOS, AlmaLinux und Arch — ohne zusätzliche Pakete.
Warum inhaltsbasierte Suche in Linux-Umgebungen wichtig ist
Namensbasierte Suchen (ls, locate) sagen Ihnen nichts darüber aus, was eine Datei enthält. In Produktionssystemen sind die entscheidenden Fragen fast immer inhaltsgetrieben:
- Welche Konfigurationsdatei setzt
max_connectionsauf einen bestimmten Wert? - Welche PHP-Datei enthält einen veralteten Funktionsaufruf, der Warnungen auslöst?
- Welche Log-Datei hat eine bestimmte IP-Adresse zu einem bestimmten Zeitstempel aufgezeichnet?
- Welche Cron-Job-Definition verweist auf einen inzwischen gelöschten Skriptpfad?
Moderne Dateimanager und GUI-Suchwerkzeuge können diese Fragen nicht effizient in großem Maßstab beantworten. Die Linux-Befehlszeile kann es — und tut dies in Millisekunden über Millionen von Dateien, wenn sie korrekt verwendet wird.
Der grep-Befehl: Primäres Werkzeug für die Inhaltssuche
grep (Global Regular Expression Print) ist das kanonische Werkzeug zur Suche von Dateiinhalten in Linux. Es liest Dateien Zeile für Zeile und gibt jede Zeile aus, die einem bestimmten Muster entspricht.
Grundlegende Syntax
grep [OPTIONS] PATTERN [FILE_OR_DIRECTORY]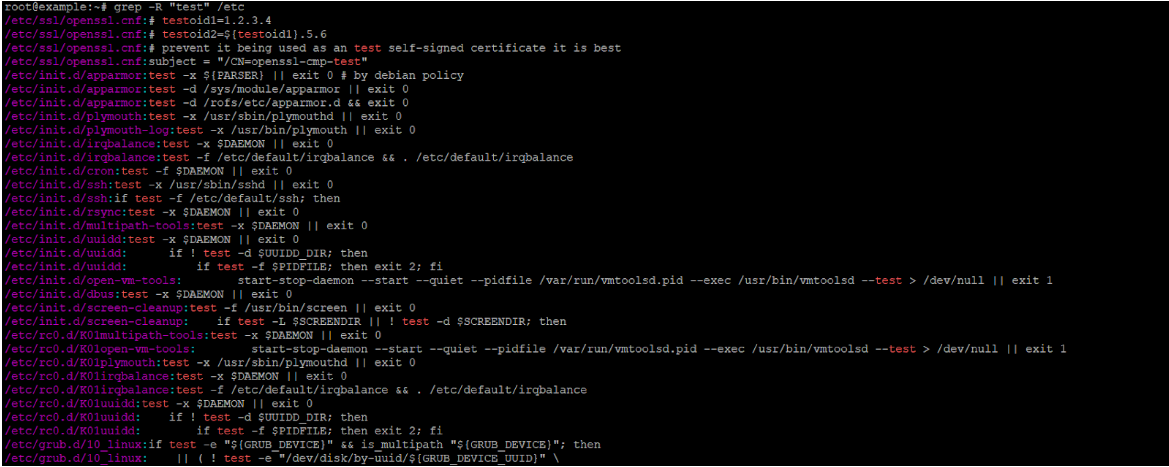
Rekursive Verzeichnissuche
Die häufigste reale Verwendung ist eine rekursive Suche über einen gesamten Verzeichnisbaum:
grep -rnw '/path/to/directory/' -e 'search_text'Erläuterung der einzelnen Flags:
| Flag | Vollständiger Name | Wirkung |
|---|---|---|
-r | --recursive | Durchsucht Unterverzeichnisse automatisch |
-n | --line-number | Stellt der Ausgabe die Zeilennummer der übereinstimmenden Zeile voran |
-w | --word-regexp | Stimmt nur mit ganzen Wörtern überein — test stimmt nicht mit testing überein |
-e | --regexp | Deklariert das Suchmuster explizit; erforderlich, wenn das Muster mit einem Bindestrich beginnt |
-i | --ignore-case | Groß-/Kleinschreibung-unabhängige Übereinstimmung (Error stimmt mit error, ERROR überein) |
-l | --files-with-matches | Gibt nur Dateinamen aus, nicht die übereinstimmenden Zeilen |
-c | --count | Gibt nur die Anzahl der übereinstimmenden Zeilen pro Datei aus |
-v | --invert-match | Gibt Zeilen zurück, die NICHT mit dem Muster übereinstimmen |
-A N | --after-context=N | Zeigt N Zeilen nach jeder Übereinstimmung als Kontext an |
-B N | --before-context=N | Zeigt N Zeilen vor jeder Übereinstimmung als Kontext an |
--include | N/A | Beschränkt die Suche auf Dateien, die einem Glob-Muster entsprechen |
--exclude | N/A | Überspringt Dateien, die einem Glob-Muster entsprechen |
Praktische grep-Beispiele
Suche nach der Zeichenkette „test1″ in /usr/games und allen Unterverzeichnissen:
grep -r "test1" /usr/gamesAlle Dateien unter /etc finden, die das Wort „network” enthalten (ganzes Wort, Groß-/Kleinschreibung-unabhängig), mit Zeilennummern:
grep -rniw "network" /etcNur die Dateinamen (nicht die übereinstimmenden Zeilen) von PHP-Dateien auflisten, die eval( enthalten:
grep -rl "eval(" /var/www/html --include="*.php"Nach einem Muster suchen und 3 Zeilen Kontext vor und nach jeder Übereinstimmung anzeigen:
grep -rn -A 3 -B 3 "FATAL" /var/log/Zählen, wie oft „PermitRootLogin” in allen SSH-Konfigurationsdateien vorkommt:
grep -rc "PermitRootLogin" /etc/ssh/Zeilen finden, die „localhost” in einer Hosts-Datei NICHT enthalten:
grep -v "localhost" /etc/hostsgrep mit regulären Ausdrücken
grep unterstützt drei Regex-Engines:
- BRE (Basic Regular Expressions) — Standardmodus
- ERE (Extended Regular Expressions) — aktiviert mit
-Eoderegrep - PCRE (Perl-Compatible Regular Expressions) — aktiviert mit
-P
# Match lines containing an IPv4 address pattern (ERE)
grep -rE '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/nginx/access.log
# Match lines with email addresses (PCRE)
grep -rP '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}' /var/www/html/Kritische Sonderfälle und Fallstricke bei grep
Binärdateien: Standardmäßig gibt grep Binary file X matches für Binärdateien aus und überspringt deren Inhalt. Verwenden Sie -a (--text), um grep zu zwingen, Binärdateien als Text zu behandeln — nützlich bei der Suche in kompilierten Konfigurationen oder Datenbank-Dumps. Bei großen Binärdateien mit Vorsicht verwenden.
Symlinks: -r folgt symbolischen Links nicht. Verwenden Sie -R (großes R), um Symlinks rekursiv zu folgen. Beachten Sie, dass dies zu Endlosschleifen führen kann, wenn zirkuläre Symlinks vorhanden sind.
Leistung bei großen Verzeichnisbäumen: grep ist standardmäßig single-threaded. Für massive Codebasen (Millionen von Dateien) sollten Sie ripgrep (rg) oder ag (The Silver Searcher) in Betracht ziehen, die multi-threaded sind und .gitignore-Muster automatisch berücksichtigen.
Null-Bytes in Dateinamen: Leiten Sie die Ausgabe von find mit -print0 weiter und verwenden Sie grep --null oder xargs -0, um Dateinamen mit Leerzeichen oder Sonderzeichen sicher zu verarbeiten.
Kodierungsprobleme: grep arbeitet auf Byte-Ebene, nicht auf Zeichenebene. Wenn Dateien UTF-16 oder andere Kodierungen verwenden, können die Ergebnisse unzuverlässig sein. Setzen Sie LANG=C oder LC_ALL=C vor dem Befehl, um byte-level-Matching zu erzwingen:
LC_ALL=C grep -r "pattern" /path/Der find-Befehl: Kombination von Datei-Metadaten und Inhaltssuche
Während grep *innerhalb* von Dateien sucht, findet find Dateien anhand ihrer Metadaten — Name, Typ, Größe, Berechtigungen, Änderungszeit — und kann dann beliebige Befehle für jedes Ergebnis ausführen. Die Kombination von find mit grep ermöglicht präzise, mehrkriterienbezogene Inhaltssuchen.
Grundlegende Syntax
find /starting/path [CRITERIA] [ACTION]Inhaltssuche mit find + grep
find /path/to/directory/ -type f -exec grep -l 'search_text' {} ;Aufbau dieses Befehls:
| Komponente | Bedeutung |
|---|---|
/path/to/directory/ | Stammverzeichnis für die Suche |
-type f | Beschränkt die Ergebnisse auf reguläre Dateien (schließt Verzeichnisse, Sockets, Geräte aus) |
-exec ... {} ; | Führt den angegebenen Befehl einmal pro gefundener Datei aus; {} wird durch den Dateinamen ersetzt |
grep -l | Gibt nur den Dateinamen aus, wenn eine Übereinstimmung gefunden wird, nicht die übereinstimmende Zeile |
Kombination von find-Kriterien für Präzision
Die eigentliche Stärke von find liegt in der Schichtung mehrerer Kriterien vor der Ausführung von grep, wodurch die Anzahl der zu durchsuchenden Dateien erheblich reduziert wird:
Nur .conf-Dateien durchsuchen, die in den letzten 7 Tagen geändert wurden:
find /etc -type f -name "*.conf" -mtime -7 -exec grep -l "timeout" {} ;Nur Dateien größer als 1MB durchsuchen:
find /var/log -type f -size +1M -exec grep -c "ERROR" {} ;Dateien eines bestimmten Benutzers durchsuchen:
find /home -type f -user john -exec grep -l "password" {} ;Dateien mit bestimmten Berechtigungen durchsuchen (für alle schreibbar):
find /var/www -type f -perm -o+w -exec grep -l "eval(" {} ;Ein Verzeichnis von der Suche ausschließen:
find /var/www -type f -not -path "*/node_modules/*" -exec grep -l "API_KEY" {} ;Verwendung von find mit xargs für bessere Leistung
Die -exec ... ;-Syntax startet für jede gefundene Datei einen neuen Prozess. Bei Verzeichnissen mit Tausenden von Dateien ist dies messbar langsamer. Die Verwendung von xargs bündelt mehrere Dateinamen in einem einzigen grep-Aufruf:
find /path/ -type f -name "*.log" -print0 | xargs -0 grep -l "connection refused"Die Flags -print0 und -0 verwenden Null-Zeichen als Trennzeichen anstelle von Zeilenumbrüchen und verarbeiten so Dateinamen mit Leerzeichen korrekt.
Der awk-Befehl: Strukturierte Inhaltssuche und -extraktion
awk ist eine vollständige Textverarbeitungssprache, nicht nur ein Suchwerkzeug. Es eignet sich hervorragend, wenn Sie nach Mustern in strukturierten Dateien suchen müssen — CSV-Daten, Log-Dateien mit festen Spalten, Konfigurationsdateien — und gleichzeitig aus den gefundenen Daten extrahieren, transformieren oder berechnen möchten.
Grundlegende Syntax
awk '/pattern/ { action }' filePraktische awk-Beispiele für die Dateiinhaltssuche
Alle Zeilen in einer Datei ausgeben, die das Wort „error” enthalten:
awk '/error/' /var/log/syslogNach einem Muster suchen und nur bestimmte Felder ausgeben (Spalte 1 und Spalte 5):
awk '/FAILED/ { print $1, $5 }' /var/log/auth.logÜber mehrere Dateien suchen und den Dateinamen mit übereinstimmenden Zeilen ausgeben:
awk '/search_term/ { print FILENAME": "$0 }' /etc/nginx/*.confGroß-/Kleinschreibung-unabhängige Suche in awk:
awk 'tolower($0) ~ /timeout/' /etc/mysql/my.cnfVorkommen eines Musters pro Datei zählen:
awk '/ERROR/ { count++ } END { print FILENAME, count }' /var/log/app.logWann awk statt grep verwendet werden sollte
awk ist die bessere Wahl, wenn:
- Sie nach Spaltenwerten filtern müssen (z. B. „Zeilen finden, bei denen Feld 3 größer als 500 ist”)
- Sie Berechnungen auf gefundenen Daten durchführen müssen
- Sie Ergebnisse aggregieren müssen (Anzahlen, Summen) über eine Datei
- Die Datei ein konsistentes Trennzeichen hat und Sie eine strukturierte Extraktion benötigen
grep bleibt schneller für reine Musterabgleichsaufgaben, bei denen Sie nur wissen müssen, *ob* und *wo* ein Muster vorhanden ist.
Werkzeugvergleich: grep vs find vs awk
| Kriterium | grep | find + grep | awk |
|---|---|---|---|
| Hauptzweck | Inhalts-Musterabgleich | Metadaten-gefilterte Inhaltssuche | Strukturierte Datenverarbeitung |
| Rekursive Suche | Ja (-r / -R) | Ja (nativ) | Nein (erfordert Shell-Schleife) |
| Metadaten-Filterung | Nein | Ja (Name, Größe, Datum, Eigentümer) | Nein |
| Unterstützung regulärer Ausdrücke | BRE, ERE, PCRE | Über grep | ERE |
| Ausgabeformatierung | Begrenzt | Begrenzt | Vollständige programmierbare Kontrolle |
| Leistung bei großen Verzeichnisbäumen | Schnell | Langsamer (Prozess pro Datei) | Mittel |
| Lernkurve | Niedrig | Mittel | Hoch |
| Bester Anwendungsfall | Schnelle Schlüsselwortsuche | Mehrkriterienbezogene Produktionsaudits | Log-Analyse, Datenextraktion |
Fortgeschrittene Techniken für Produktionsumgebungen
Suche in komprimierten Log-Dateien
Auf Servern, auf denen Logs rotiert und komprimiert werden, verwenden Sie zgrep, um .gz-Dateien zu durchsuchen, ohne sie zuerst zu dekomprimieren:
zgrep "segfault" /var/log/syslog.*.gzSuche in tar-Archiven ohne Entpacken
tar -xOf archive.tar.gz | grep "search_pattern"Kombination von grep mit sort und uniq für Häufigkeitsanalysen
Die häufigsten Fehlermeldungen in einer Log-Datei finden:
grep "ERROR" /var/log/app.log | sort | uniq -c | sort -rn | head -20Binärdateien ausschließen und auf Quellcode fokussieren
grep -r --include="*.py" --include="*.js" --include="*.php" "TODO" /var/www/Echtzeit-Inhaltsüberwachung mit grep
Leiten Sie tail -f in grep weiter, um die Live-Log-Ausgabe auf bestimmte Muster zu überwachen:
tail -f /var/log/nginx/error.log | grep --line-buffered "upstream"Das Flag --line-buffered zwingt grep, die Ausgabe nach jeder Zeile zu leeren, was beim Weiterleiten aus einem kontinuierlichen Stream unerlässlich ist.
Anwendungsfälle für Sicherheitsaudits
Die inhaltsbasierte Dateisuche ist eine Kerntechnik bei der Linux-Sicherheitshärtung. Auf einem Dedicated Server oder VPS sind diese Muster betrieblich kritisch:
Nach fest codierten Passwörtern in Webanwendungsdateien suchen:
grep -rniE "(password|passwd|pwd)s*=s*['"][^'"]{3,}" /var/www/ --include="*.php"Für alle lesbaren privaten Schlüsseldateien suchen:
find / -name "*.pem" -o -name "*.key" | xargs grep -l "PRIVATE KEY"PHP-Webshells durch Suche nach häufigen Shell-Funktionskombinationen erkennen:
grep -rPl "evals*(s*(base64_decode|gzinflate|str_rot13)" /var/www/SSH authorized_keys-Dateien aller Benutzer prüfen:
find /home -name "authorized_keys" -exec grep -H "." {} ;Beim Betrieb eines VPS mit cPanel sind diese Audits besonders wichtig, da cPanel-Umgebungen mehrere Konten hosten und eine Kompromittierung eines Kontos andere beeinträchtigen kann.
Leistungsoptimierung für großangelegte Suchen
Suchtiefe begrenzen, um das unnötige Durchsuchen tiefer Verzeichnisbäume zu vermeiden:
find /var/www -maxdepth 3 -type f -name "*.php" -exec grep -l "eval(" {} ;ripgrep für geschwindigkeitskritische Aufgaben verwenden. Obwohl hier nicht ausführlich behandelt, ist rg bei großen Codebasen aufgrund von Parallelismus und intelligenterer Dateifilterung 3–10x schneller als grep. Es ist in den meisten Distributions-Repositories verfügbar:
apt install ripgrep # Debian/Ubuntu
yum install ripgrep # CentOS/RHELSuche mit time profilieren, um verschiedene Ansätze zu benchmarken:
time grep -r "pattern" /large/directory/Suche in /proc und /sys vermeiden — diese virtuellen Dateisysteme können zu Hängen führen oder bedeutungslose Ausgaben erzeugen:
grep -r --exclude-dir={proc,sys,dev} "pattern" /Den richtigen Ansatz wählen: Entscheidungsmatrix
| Szenario | Empfohlener Befehl | |
|---|---|---|
| Schnelle Schlüsselwortsuche in einem Verzeichnis | grep -rn "keyword" /path/ | |
| Groß-/Kleinschreibung-unabhängige Ganzwortsuche | grep -rniw "keyword" /path/ | |
| Nur bestimmte Dateitypen durchsuchen | grep -r --include="*.conf" "keyword" /path/ | |
| Kürzlich geänderte Dateien durchsuchen | find /path -mtime -1 -exec grep -l "keyword" {} ; | |
| Große Verzeichnisbäume effizient durchsuchen | `find /path -print0 | xargs -0 grep -l "keyword"` |
| Strukturierte Daten aus Logs extrahieren | awk '/pattern/ { print $1, $NF }' logfile | |
| Komprimierte Logs durchsuchen | zgrep "keyword" /var/log/*.gz | |
| Echtzeit-Log-Überwachung | `tail -f /var/log/file.log | grep –line-buffered "pattern"` |
| Sicherheitsaudit für sensible Zeichenketten | grep -rPl "eval(base64_decode" /var/www/ |
Wichtige technische Erkenntnisse
- Verwenden Sie
grep -rniwals Standard für rekursive Suchen — es verarbeitet Groß-/Kleinschreibung, ganze Wörter und Zeilennummern in einem Durchgang. - Verwenden Sie immer
-print0mitfindund-0mitxargs, um Dateinamen mit Leerzeichen oder Sonderzeichen sicher zu verarbeiten. - Verwenden Sie
-exec grep ... {} +(Pluszeichen statt Semikolon), um mehrere Dateien progrep-Aufruf zu bündeln und den Prozessaufwand zu reduzieren. grep -R(großes R) folgt Symlinks;grep -rnicht — wissen Sie, welches Verhalten Ihre Umgebung erfordert.- Setzen Sie
LC_ALL=Cvorgrepin Skripten, um locale-bedingte Leistungseinbußen und Kodierungsüberraschungen zu vermeiden. - Beschränken Sie Suchen mit
--includeund--exclude-dir, um irrelevante Dateien zu eliminieren, bevor der Musterabgleich beginnt. - Für Multi-Account-Hosting-Umgebungen, die über VPS Control Panels verwaltet werden, planen Sie Inhaltsaudits als Cron-Jobs mit diesen Befehlen, um Sicherheitsprüfungen zu automatisieren.
- In Shared Web Hosting-Umgebungen können Inhaltssuche-Berechtigungen vom Hosting-Anbieter eingeschränkt sein — verwenden Sie diese Befehle nur innerhalb des eigenen Kontodateibaums.
Häufig gestellte Fragen
Was ist der schnellste Weg, um auf einem Linux-Server nach Text in allen Dateien zu suchen?
Für Geschwindigkeit bei großen Verzeichnisbäumen verwenden Sie grep -r --include="*.ext" "pattern" /path/ mit Dateitypbeschränkungen oder installieren Sie ripgrep (rg "pattern" /path/), das Multi-Threading verwendet und bei großen Codebasen typischerweise 3–10x schneller als Standard-grep ist.
Wie suche ich nach einer Zeichenkette in Dateien, aber schließe bestimmte Verzeichnisse aus?
Verwenden Sie die Option --exclude-dir von grep: grep -r --exclude-dir={.git,node_modules,vendor} "pattern" /path/. Für find-basierte Suchen verwenden Sie -not -path "*/dirname/*" vor der -exec-Klausel.
Was ist der Unterschied zwischen grep -r und grep -R?
grep -r führt eine rekursive Suche durch, folgt aber keinen symbolischen Links. grep -R führt dieselbe rekursive Suche durch und folgt zusätzlich Symlinks. Verwenden Sie -R nur, wenn Sie sicher sind, dass im Zielverzeichnisbaum keine zirkulären Symlinks vorhanden sind.
Kann ich nach Inhalten in komprimierten .gz-Log-Dateien suchen, ohne sie zu dekomprimieren?
Ja. Verwenden Sie zgrep "pattern" /var/log/file.log.gz für einzelne Dateien oder zgrep "pattern" /var/log/*.gz für mehrere komprimierte Dateien. Das Ausgabeformat ist identisch mit dem Standard-grep.
Wie suche ich nach einem mehrzeiligen Muster in Linux-Dateien?
Standard-grep gleicht Zeile für Zeile ab und kann nativ keine Muster über mehrere Zeilen hinweg abgleichen. Verwenden Sie grep -P mit Perl-kompatiblen regulären Ausdrücken und n für Zeilenumbrüche, oder verwenden Sie pcregrep -M "line1nline2" file, wenn pcregrep verfügbar ist. Für komplexe mehrzeilige Extraktionen ist awk mit RS-Neudefinition (Datensatztrennzeichen) oft die lesbarste Lösung.


