 български
български English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 от всички хостинг услуги
от всички хостинг услугиКак да намерите файл по съдържание в Linux: grep, find и awk обяснени
Търсенето на файл по съдържание в Linux означава сканиране на данните на файла — не само имена на файлове или метаданни — с помощта на инструменти като grep, find и awk за съпоставяне на текстови шаблони, низове или регулярни изрази в един или много файлове едновременно. Това е фундаментално различно от търсенето по име и е правилният подход, когато знаете какво *съдържа* даден файл, но не знаете къде се намира или как се казва.
За всеки, който управлява среда за VPS Хостинг, търсенето на файлове по съдържание е ежедневна оперативна необходимост: намиране на неправилно конфигурирани директиви в /etc, одит на лог файлове за шаблони на грешки или издирване на твърдо кодирани идентификационни данни в дървета с изходен код на приложения. Командите, разгледани в това ръководство, работят идентично при всички основни Linux дистрибуции — Debian, Ubuntu, CentOS, AlmaLinux и Arch — без необходимост от допълнителни пакети.
Защо търсенето по съдържание е важно в Linux среди
Търсенето по имена на файлове (ls, locate) не ви казва нищо за съдържанието на файла. В производствени системи критичните въпроси са почти винаги свързани със съдържанието:
- Кой конфигурационен файл задава
max_connectionsна конкретна стойност? - Кой PHP файл съдържа остаряло извикване на функция, което генерира предупреждения?
- Кой лог файл е записал конкретен IP адрес в даден момент от времето?
- Коя дефиниция на cron задача препраща към вече изтрит път на скрипт?
Съвременните файлови мениджъри и GUI инструменти за търсене не могат да отговорят ефективно на тези въпроси в голям мащаб. Командният ред на Linux може — и го прави за милисекунди при милиони файлове, когато се използва правилно.
Командата grep: Основен инструмент за търсене на съдържание
grep (Global Regular Expression Print) е каноничният инструмент за търсене на съдържание на файлове в Linux. Той чете файловете ред по ред и отпечатва всеки ред, съответстващ на даден шаблон.
Основен синтаксис
grep [OPTIONS] PATTERN [FILE_OR_DIRECTORY]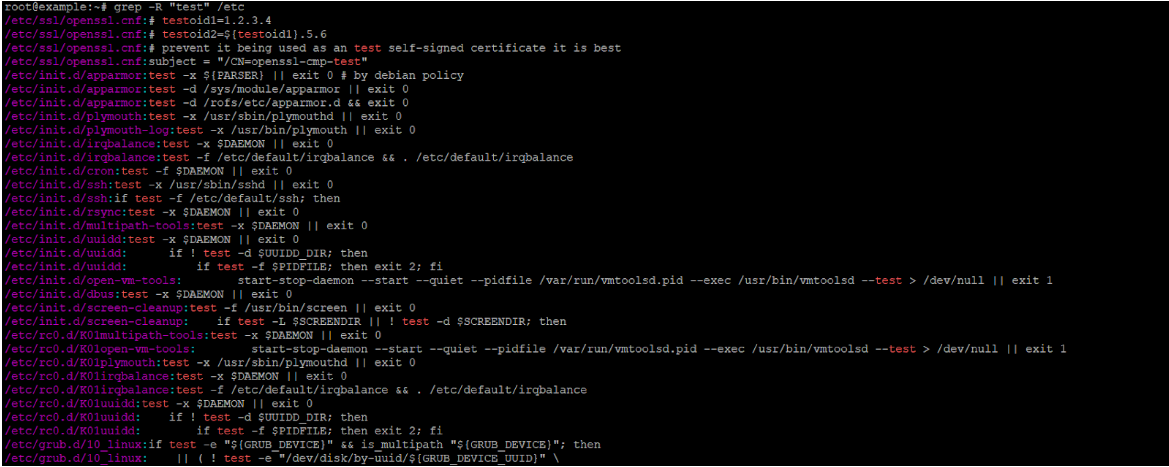
Рекурсивно търсене в директория
Най-честото реално използване е рекурсивно търсене в цяло дърво от директории:
grep -rnw '/path/to/directory/' -e 'search_text'Разбивка на всеки флаг:
| Флаг | Пълно наименование | Ефект |
|---|---|---|
-r | --recursive | Автоматично влиза в поддиректории |
-n | --line-number | Добавя номера на съответстващия ред в изхода |
-w | --word-regexp | Съпоставя само цели думи — test няма да съответства на testing |
-e | --regexp | Изрично декларира шаблона за търсене; необходимо е, когато шаблонът започва с тире |
-i | --ignore-case | Съпоставяне без разлика на главни/малки букви (Error съответства на error, ERROR) |
-l | --files-with-matches | Отпечатва само имената на файловете, не съответстващите редове |
-c | --count | Отпечатва само броя на съответстващите редове за всеки файл |
-v | --invert-match | Връща редове, които НЕ съответстват на шаблона |
-A N | --after-context=N | Показва N реда след всяко съвпадение за контекст |
-B N | --before-context=N | Показва N реда преди всяко съвпадение за контекст |
--include | N/A | Ограничава търсенето до файлове, съответстващи на glob шаблон |
--exclude | N/A | Пропуска файлове, съответстващи на glob шаблон |
Практически примери с grep
Търсене на низа "test1" в /usr/games и всички поддиректории:
grep -r "test1" /usr/gamesНамиране на всички файлове в /etc, съдържащи думата "network" (цяла дума, без разлика на главни/малки букви), с показване на номерата на редовете:
grep -rniw "network" /etcИзвеждане само на имената на файловете (не на съответстващите редове) на PHP файлове, съдържащи eval(:
grep -rl "eval(" /var/www/html --include="*.php"Търсене на шаблон и показване на 3 реда контекст преди и след всяко съвпадение:
grep -rn -A 3 -B 3 "FATAL" /var/log/Броене на колко пъти се среща "PermitRootLogin" в всички SSH конфигурационни файлове:
grep -rc "PermitRootLogin" /etc/ssh/Намиране на редове, които НЕ съдържат "localhost" в hosts файл:
grep -v "localhost" /etc/hostsgrep с регулярни изрази
grep поддържа три regex машини:
- BRE (Basic Regular Expressions) — режим по подразбиране
- ERE (Extended Regular Expressions) — активира се с
-Eилиegrep - PCRE (Perl-Compatible Regular Expressions) — активира се с
-P
# Match lines containing an IPv4 address pattern (ERE)
grep -rE '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/nginx/access.log
# Match lines with email addresses (PCRE)
grep -rP '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}' /var/www/html/Критични гранични случаи и клопки при grep
Двоични файлове: По подразбиране grep ще отпечата Binary file X matches за двоични файлове и ще пропусне съдържанието им. Използвайте -a (--text), за да принудите grep да третира двоичните файлове като текст — полезно при търсене в компилирани конфигурации или дъмпове на бази данни. Използвайте с внимание при големи двоични файлове.
Символни връзки: -r не следва символни връзки. Използвайте -R (главно R), за да следвате символните връзки рекурсивно. Имайте предвид, че това може да създаде безкрайни цикли, ако съществуват кръгови символни връзки.
Производителност при големи дървета: grep е еднонишков по подразбиране. За масивни кодови бази (милиони файлове), обмислете ripgrep (rg) или ag (The Silver Searcher), които са многонишкови и автоматично зачитат .gitignore шаблони.
Нулеви байтове в имената на файловете: Пренасочете изхода на find с -print0 и използвайте grep --null или xargs -0 за безопасна обработка на имена на файлове, съдържащи интервали или специални символи.
Проблеми с кодировката: grep работи с байтове, не с символи. Ако файловете използват UTF-16 или други кодировки, резултатите може да са ненадеждни. Задайте LANG=C или LC_ALL=C преди командата, за да принудите съпоставяне на ниво байтове:
LC_ALL=C grep -r "pattern" /path/Командата find: Комбиниране на метаданни на файлове и търсене по съдържание
Докато grep търси *вътре* в файловете, find локализира файлове въз основа на техните метаданни — име, тип, размер, разрешения, време на промяна — и след това може да изпълни произволни команди за всеки резултат. Комбинирането на find с grep ви дава прецизни търсения по съдържание с множество критерии.
Основен синтаксис
find /starting/path [CRITERIA] [ACTION]Търсене на съдържание с find + grep
find /path/to/directory/ -type f -exec grep -l 'search_text' {} ;Анатомия на тази команда:
| Компонент | Значение |
|---|---|
/path/to/directory/ | Основна директория за търсенето |
-type f | Ограничава резултатите само до обикновени файлове (изключва директории, сокети, устройства) |
-exec ... {} ; | Изпълнява посочената команда веднъж за всеки намерен файл; {} се заменя с името на файла |
grep -l | Отпечатва само името на файла при намерено съвпадение, не съответстващия ред |
Комбиниране на критерии на find за прецизност
Истинската сила на find е в наслагването на множество критерии преди изпълнението на grep, което драстично намалява броя на файловете, които трябва да бъдат сканирани:
Търсене само в .conf файлове, променени през последните 7 дни:
find /etc -type f -name "*.conf" -mtime -7 -exec grep -l "timeout" {} ;Търсене само в файлове по-големи от 1MB:
find /var/log -type f -size +1M -exec grep -c "ERROR" {} ;Търсене в файлове, притежавани от конкретен потребител:
find /home -type f -user john -exec grep -l "password" {} ;Търсене в файлове с конкретни разрешения (достъпни за запис от всички):
find /var/www -type f -perm -o+w -exec grep -l "eval(" {} ;Изключване на директория от търсенето:
find /var/www -type f -not -path "*/node_modules/*" -exec grep -l "API_KEY" {} ;Използване на find с xargs за по-добра производителност
Синтаксисът -exec ... ; стартира нов процес за всеки намерен файл. При директории с хиляди файлове това е измеримо по-бавно. Използването на xargs групира множество имена на файлове в едно извикване на grep:
find /path/ -type f -name "*.log" -print0 | xargs -0 grep -l "connection refused"Флаговете -print0 и -0 използват нулеви символи като разделители вместо нови редове, като правилно обработват имена на файлове с интервали.
Командата awk: Структурирано търсене и извличане на съдържание
awk е пълноценен език за обработка на текст, не просто инструмент за търсене. Той се отличава, когато трябва да търсите шаблони в структурирани файлове — CSV данни, лог файлове с фиксирани колони, конфигурационни файлове — и едновременно да извличате, трансформирате или изчислявате от съответстващите данни.
Основен синтаксис
awk '/pattern/ { action }' fileПрактически примери с awk за търсене на съдържание на файлове
Отпечатване на всички редове във файл, съдържащи думата "error":
awk '/error/' /var/log/syslogТърсене на шаблон и отпечатване само на конкретни полета (колона 1 и колона 5):
awk '/FAILED/ { print $1, $5 }' /var/log/auth.logТърсене в множество файлове и отпечатване на името на файла заедно със съответстващите редове:
awk '/search_term/ { print FILENAME": "$0 }' /etc/nginx/*.confТърсене без разлика на главни/малки букви в awk:
awk 'tolower($0) ~ /timeout/' /etc/mysql/my.cnfБроене на срещанията на шаблон за всеки файл:
awk '/ERROR/ { count++ } END { print FILENAME, count }' /var/log/app.logКога да използвате awk вместо grep
awk е по-добрият избор, когато:
- Трябва да филтрирате по стойност на колона (напр. "намери редове, в които поле 3 е по-голямо от 500")
- Трябва да извършвате аритметика върху съответстващите данни
- Трябва да агрегирате резултати (броения, суми) в даден файл
- Файлът има последователен разделител и се нуждаете от структурирано извличане
grep остава по-бърз за задачи за чисто съпоставяне на шаблони, при които трябва само да знаете *дали* и *къде* съществува даден шаблон.
Сравнение на инструментите: grep срещу find срещу awk
| Критерий | grep | find + grep | awk |
|---|---|---|---|
| Основна цел | Съпоставяне на шаблони в съдържание | Търсене на съдържание с филтриране по метаданни | Обработка на структурирани данни |
| Рекурсивно търсене | Да (-r / -R) | Да (вградено) | Не (изисква shell цикъл) |
| Филтриране по метаданни | Не | Да (име, размер, дата, собственик) | Не |
| Поддръжка на регулярни изрази | BRE, ERE, PCRE | Чрез grep | ERE |
| Форматиране на изхода | Ограничено | Ограничено | Пълен програмируем контрол |
| Производителност при големи дървета | Бърза | По-бавна (процес за всеки файл) | Умерена |
| Крива на обучение | Ниска | Средна | Висока |
| Най-добър случай на употреба | Бързо търсене по ключова дума | Производствени одити с множество критерии | Анализ на логове, извличане на данни |
Разширени техники за производствени среди
Търсене в компресирани лог файлове
На сървъри, където логовете се ротират и компресират, използвайте zgrep за търсене в .gz файлове без предварителното им декомпресиране:
zgrep "segfault" /var/log/syslog.*.gzТърсене вътре в tar архиви без извличане
tar -xOf archive.tar.gz | grep "search_pattern"Комбиниране на grep с sort и uniq за анализ на честотата
Намиране на най-честите съобщения за грешки в лог файл:
grep "ERROR" /var/log/app.log | sort | uniq -c | sort -rn | head -20Изключване на двоични файлове и фокусиране върху изходен код
grep -r --include="*.py" --include="*.js" --include="*.php" "TODO" /var/www/Наблюдение на съдържание в реално време с grep
Пренасочете tail -f към grep за наблюдение на живия изход на логовете за конкретни шаблони:
tail -f /var/log/nginx/error.log | grep --line-buffered "upstream"Флагът --line-buffered принуждава grep да изчиства изхода след всеки ред, което е от съществено значение при пренасочване от непрекъснат поток.
Случаи на употреба при одит на сигурността
Търсенето на файлове по съдържание е основна техника при втвърдяване на сигурността на Linux. На Dedicated Server или VPS тези шаблони са оперативно критични:
Сканиране за твърдо кодирани пароли в файлове на уеб приложения:
grep -rniE "(password|passwd|pwd)s*=s*['"][^'"]{3,}" /var/www/ --include="*.php"Намиране на файлове с частни ключове, достъпни за четене от всички:
find / -name "*.pem" -o -name "*.key" | xargs grep -l "PRIVATE KEY"Откриване на PHP уеб шелове чрез сканиране за комбинации от общи shell функции:
grep -rPl "evals*(s*(base64_decode|gzinflate|str_rot13)" /var/www/Одит на SSH authorized_keys файлове за всички потребители:
find /home -name "authorized_keys" -exec grep -H "." {} ;При работа с VPS с cPanel, тези одити са особено важни, тъй като cPanel средите хостват множество акаунти и компрометирането на един може да засегне останалите.
Оптимизация на производителността за търсения в голям мащаб
Ограничете дълбочината на търсене, за да избегнете ненужното обхождане на дълбоки дървета от директории:
find /var/www -maxdepth 3 -type f -name "*.php" -exec grep -l "eval(" {} ;Използвайте ripgrep за задачи, критични по отношение на скоростта. Макар да не е разгледан подробно тук, rg е 3–10 пъти по-бърз от grep при големи кодови бази благодарение на паралелизма и по-интелигентното филтриране на файлове. Наличен е в повечето хранилища на дистрибуции:
apt install ripgrep # Debian/Ubuntu
yum install ripgrep # CentOS/RHELПрофилирайте търсенето си с time за сравнителен анализ на различни подходи:
time grep -r "pattern" /large/directory/Избягвайте търсене в /proc и /sys — тези виртуални файлови системи могат да причинят блокиране или да генерират безсмислен изход:
grep -r --exclude-dir={proc,sys,dev} "pattern" /Избор на правилния подход: Матрица за вземане на решения
| Сценарий | Препоръчана команда | |
|---|---|---|
| Бързо търсене по ключова дума в директория | grep -rn "keyword" /path/ | |
| Търсене на цяла дума без разлика на главни/малки букви | grep -rniw "keyword" /path/ | |
| Търсене само в конкретни типове файлове | grep -r --include="*.conf" "keyword" /path/ | |
| Търсене в наскоро променени файлове | find /path -mtime -1 -exec grep -l "keyword" {} ; | |
| Ефективно търсене в големи дървета от файлове | `find /path -print0 | xargs -0 grep -l "keyword"` |
| Извличане на структурирани данни от логове | awk '/pattern/ { print $1, $NF }' logfile | |
| Търсене в компресирани логове | zgrep "keyword" /var/log/*.gz | |
| Наблюдение на логове в реално време | `tail -f /var/log/file.log | grep –line-buffered "pattern"` |
| Одит на сигурността за чувствителни низове | grep -rPl "eval(base64_decode" /var/www/ |
Основни технически изводи
- Използвайте
grep -rniwкато стандартно рекурсивно търсене — обработва главни/малки букви, цели думи и номера на редове в един проход. - Винаги използвайте
-print0сfindи-0сxargsза безопасна обработка на имена на файлове, съдържащи интервали или специални символи. - Използвайте
-exec grep ... {} +(знак плюс вместо точка и запетая) за групиране на множество файлове в едно извикване наgrepи намаляване на натоварването от процеси. grep -R(главно R) следва символни връзки;grep -rне следва — знайте кое поведение изисква вашата среда.- Задайте
LC_ALL=Cпредиgrepв скриптове, за да избегнете свързани с локала проблеми с производителността и изненади с кодировката. - Ограничете търсенията с
--includeи--exclude-dir, за да изключите нерелевантни файлове преди началото на съпоставянето на шаблони. - За среди с множество акаунти, управлявани чрез VPS Control Panels, планирайте одити на съдържанието като cron задачи, използвайки тези команди за автоматизиране на проверките за сигурност.
- В среди за Споделен уеб хостинг, разрешенията за търсене на съдържание може да са ограничени от хостинг доставчика — използвайте тези команди само в рамките на дървото от файлове на вашия собствен акаунт.
Често задавани въпроси
Кой е най-бързият начин за търсене на текст във всички файлове на Linux сървър?
За скорост при големи дървета от файлове използвайте grep -r --include="*.ext" "pattern" /path/ с ограничения за типа файлове или инсталирайте ripgrep (rg "pattern" /path/), който използва многонишковост и обикновено е 3–10 пъти по-бърз от стандартния grep при големи кодови бази.
Как да търся низ в файлове, но да изключа определени директории?
Използвайте опцията --exclude-dir на grep: grep -r --exclude-dir={.git,node_modules,vendor} "pattern" /path/. За търсения, базирани на find, използвайте -not -path "*/dirname/*" преди клаузата -exec.
Каква е разликата между grep -r и grep -R?
grep -r извършва рекурсивно търсене, но не следва символни връзки. grep -R извършва същото рекурсивно търсене и допълнително следва символни връзки. Използвайте -R само когато сте сигурни, че в целевото дърво от директории не съществуват кръгови символни връзки.
Мога ли да търся съдържание в компресирани .gz лог файлове без да ги декомпресирам?
Да. Използвайте zgrep "pattern" /var/log/file.log.gz за отделни файлове или zgrep "pattern" /var/log/*.gz за множество компресирани файлове. Форматът на изхода е идентичен с този на стандартния grep.
Как да търся многоредов шаблон в Linux файлове?
Стандартният grep съпоставя ред по ред и не може нативно да съпоставя шаблони, обхващащи множество редове. Използвайте grep -P с Perl-съвместими регулярни изрази и n за нови редове, или използвайте pcregrep -M "line1nline2" file ако pcregrep е наличен. За сложно многоредово извличане, awk с предефиниране на RS (разделител на записи) е често най-четимото решение.


