 中文 (中国)
中文 (中国) English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia 





如何在Linux中按内容查找文件:grep、find和awk详解
在Linux中按内容搜索文件意味着扫描文件数据——而不仅仅是文件名或元数据——使用grep、find和awk等工具在一个或多个文件中同时匹配文本模式、字符串或正则表达式。这与基于名称的搜索有本质区别,当您知道文件*包含*什么内容但不知道它在哪里或叫什么名字时,这是正确的方法。
对于管理VPS Hosting环境的人来说,基于内容的文件搜索是日常运维的必要操作:在/etc中定位配置错误的指令、审计日志文件中的错误模式,或在应用程序源代码树中查找硬编码的凭据。本指南中介绍的命令在所有主流Linux发行版上均可完全相同地使用——Debian、Ubuntu、CentOS、AlmaLinux和Arch——无需安装额外软件包。
为什么基于内容的搜索在Linux环境中至关重要
基于文件名的搜索(ls、locate)无法告诉您文件包含什么内容。在生产系统中,关键问题几乎总是与内容相关:
- 哪个配置文件将
max_connections设置为特定值? - 哪个PHP文件包含正在抛出警告的已废弃函数调用?
- 哪个日志文件在给定时间戳记录了特定IP地址?
- 哪个cron任务定义引用了已被删除的脚本路径?
现代文件管理器和GUI搜索工具无法在大规模场景下高效回答这些问题。Linux命令行可以——在正确使用的情况下,能在数毫秒内搜索数百万个文件。
grep命令:内容搜索的主要工具
grep(Global Regular Expression Print)是Linux中搜索文件内容的标准工具。它逐行读取文件,并打印与给定模式匹配的任何行。
核心语法
grep [OPTIONS] PATTERN [FILE_OR_DIRECTORY]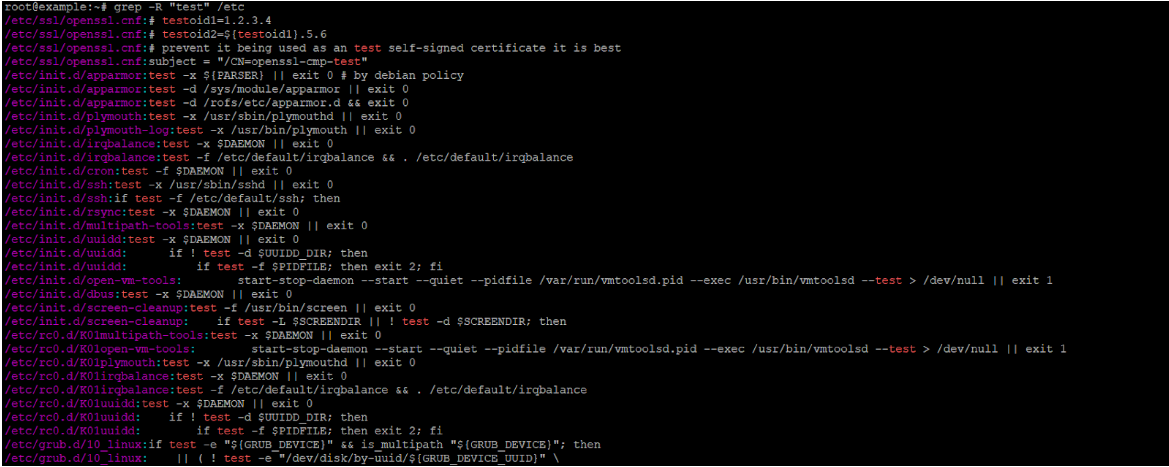
递归目录搜索
最常见的实际用法是对整个目录树进行递归搜索:
grep -rnw '/path/to/directory/' -e 'search_text'各标志说明:
| 标志 | 完整名称 | 效果 |
|---|---|---|
-r | --recursive | 自动进入子目录 |
-n | --line-number | 在输出中显示匹配行的行号 |
-w | --word-regexp | 仅匹配完整单词——test不会匹配testing |
-e | --regexp | 明确声明搜索模式;当模式以连字符开头时必须使用 |
-i | --ignore-case | 不区分大小写匹配(Error匹配error、ERROR) |
-l | --files-with-matches | 仅打印文件名,不打印匹配行 |
-c | --count | 仅打印每个文件中匹配行的数量 |
-v | --invert-match | 返回不匹配该模式的行 |
-A N | --after-context=N | 显示每个匹配项后的N行上下文 |
-B N | --before-context=N | 显示每个匹配项前的N行上下文 |
--include | N/A | 将搜索限制为匹配glob模式的文件 |
--exclude | N/A | 跳过匹配glob模式的文件 |
grep实用示例
在/usr/games及所有子目录中搜索字符串”test1″:
grep -r "test1" /usr/games查找/etc下所有包含单词”network”(完整单词,不区分大小写)的文件,并显示行号:
grep -rniw "network" /etc仅列出包含eval(的PHP文件的文件名(不显示匹配行):
grep -rl "eval(" /var/www/html --include="*.php"搜索模式并在每个匹配项前后显示3行上下文:
grep -rn -A 3 -B 3 "FATAL" /var/log/统计”PermitRootLogin”在所有SSH配置文件中出现的次数:
grep -rc "PermitRootLogin" /etc/ssh/在hosts文件中查找不包含”localhost”的行:
grep -v "localhost" /etc/hostsgrep与正则表达式
grep支持三种正则表达式引擎:
- BRE(基本正则表达式)——默认模式
- ERE(扩展正则表达式)——通过
-E或egrep激活 - PCRE(Perl兼容正则表达式)——通过
-P激活
# Match lines containing an IPv4 address pattern (ERE)
grep -rE '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/nginx/access.log
# Match lines with email addresses (PCRE)
grep -rP '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}' /var/www/html/grep的关键边界情况与注意事项
二进制文件:默认情况下,grep会对二进制文件打印Binary file X matches并跳过其内容。使用-a(--text)强制grep将二进制文件视为文本——在搜索已编译的配置文件或数据库转储时很有用。在大型二进制文件上使用时需谨慎。
符号链接:-r不会跟随符号链接。使用-R(大写R)递归跟随符号链接。请注意,如果存在循环符号链接,这可能导致无限循环。
大型目录树的性能:grep默认是单线程的。对于大型代码库(数百万个文件),考虑使用ripgrep(rg)或ag(The Silver Searcher),它们是多线程的,并自动遵循.gitignore模式。
文件名中的空字节:将find输出通过管道传递给-print0,并使用grep --null或xargs -0安全处理包含空格或特殊字符的文件名。
编码问题:grep按字节而非字符操作。如果文件使用UTF-16或其他编码,结果可能不可靠。在命令前设置LANG=C或LC_ALL=C以强制字节级匹配:
LC_ALL=C grep -r "pattern" /path/find命令:结合文件元数据与内容搜索
grep在文件*内部*搜索,而find则根据文件的元数据——名称、类型、大小、权限、修改时间——定位文件,并可对每个结果执行任意命令。将find与grep结合使用,可实现精确的多条件内容搜索。
核心语法
find /starting/path [CRITERIA] [ACTION]使用find + grep进行内容搜索
find /path/to/directory/ -type f -exec grep -l 'search_text' {} ;该命令的结构说明:
| 组件 | 含义 |
|---|---|
/path/to/directory/ | 搜索的根目录 |
-type f | 将结果限制为普通文件(排除目录、套接字、设备) |
-exec ... {} ; | 对每个匹配文件执行一次指定命令;{}被替换为文件名 |
grep -l | 找到匹配项时仅打印文件名,不打印匹配行 |
结合find条件实现精确搜索
find的真正强大之处在于在执行grep之前叠加多个条件,从而大幅减少需要扫描的文件数量:
仅搜索过去7天内修改过的.conf文件:
find /etc -type f -name "*.conf" -mtime -7 -exec grep -l "timeout" {} ;仅搜索大于1MB的文件:
find /var/log -type f -size +1M -exec grep -c "ERROR" {} ;搜索特定用户拥有的文件:
find /home -type f -user john -exec grep -l "password" {} ;搜索具有特定权限的文件(全局可写):
find /var/www -type f -perm -o+w -exec grep -l "eval(" {} ;从搜索中排除某个目录:
find /var/www -type f -not -path "*/node_modules/*" -exec grep -l "API_KEY" {} ;使用find与xargs提升性能
-exec ... ;语法会为每个找到的文件生成一个新进程。在包含数千个文件的目录中,这会明显变慢。使用xargs可将多个文件名批量传入单次grep调用:
find /path/ -type f -name "*.log" -print0 | xargs -0 grep -l "connection refused"-print0和-0标志使用空字符而非换行符作为分隔符,可正确处理包含空格的文件名。
awk命令:结构化内容搜索与提取
awk是一种完整的文本处理语言,而不仅仅是搜索工具。当您需要在结构化文件——CSV数据、具有固定列的日志文件、配置文件——中搜索模式,并同时从匹配数据中提取、转换或计算时,它表现出色。
核心语法
awk '/pattern/ { action }' fileawk文件内容搜索实用示例
打印文件中包含单词”error”的所有行:
awk '/error/' /var/log/syslog搜索模式并仅打印特定字段(第1列和第5列):
awk '/FAILED/ { print $1, $5 }' /var/log/auth.log跨多个文件搜索并打印文件名与匹配行:
awk '/search_term/ { print FILENAME": "$0 }' /etc/nginx/*.confawk中的不区分大小写搜索:
awk 'tolower($0) ~ /timeout/' /etc/mysql/my.cnf统计每个文件中某模式的出现次数:
awk '/ERROR/ { count++ } END { print FILENAME, count }' /var/log/app.log何时使用awk而非grep
awk在以下情况下是更好的选择:
- 需要按列值过滤(例如,”查找第3个字段大于500的行”)
- 需要对匹配数据执行算术运算
- 需要对文件中的结果进行聚合(计数、求和)
- 文件具有一致的分隔符,且需要结构化提取
对于纯模式匹配任务(仅需知道模式是否存在及其位置),grep仍然更快。
工具对比:grep vs find vs awk
| 标准 | grep | find + grep | awk |
|---|---|---|---|
| 主要用途 | 内容模式匹配 | 元数据过滤的内容搜索 | 结构化数据处理 |
| 递归搜索 | 是(-r / -R) | 是(原生支持) | 否(需要shell循环) |
| 元数据过滤 | 否 | 是(名称、大小、日期、所有者) | 否 |
| 正则表达式支持 | BRE、ERE、PCRE | 通过grep | ERE |
| 输出格式化 | 有限 | 有限 | 完全可编程控制 |
| 大型目录树性能 | 快 | 较慢(每文件一个进程) | 中等 |
| 学习曲线 | 低 | 中 | 高 |
| 最佳使用场景 | 快速关键词搜索 | 多条件生产审计 | 日志解析、数据提取 |
生产环境的高级技巧
搜索压缩日志文件
在日志经过轮转和压缩的服务器上,使用zgrep搜索.gz文件而无需先解压:
zgrep "segfault" /var/log/syslog.*.gz在不解压的情况下搜索tar归档文件内容
tar -xOf archive.tar.gz | grep "search_pattern"结合grep、sort和uniq进行频率分析
查找日志文件中最常见的错误消息:
grep "ERROR" /var/log/app.log | sort | uniq -c | sort -rn | head -20排除二进制文件并专注于源代码
grep -r --include="*.py" --include="*.js" --include="*.php" "TODO" /var/www/使用grep进行实时内容监控
将tail -f通过管道传入grep,以监控实时日志输出中的特定模式:
tail -f /var/log/nginx/error.log | grep --line-buffered "upstream"--line-buffered标志强制grep在每行后刷新输出,这在从连续流中通过管道传输时至关重要。
安全审计使用场景
基于内容的文件搜索是Linux安全加固的核心技术。在Dedicated Server或VPS上,这些模式在运维中至关重要:
扫描Web应用程序文件中的硬编码密码:
grep -rniE "(password|passwd|pwd)s*=s*['"][^'"]{3,}" /var/www/ --include="*.php"查找全局可读的私钥文件:
find / -name "*.pem" -o -name "*.key" | xargs grep -l "PRIVATE KEY"通过扫描常见shell函数组合检测PHP webshell:
grep -rPl "evals*(s*(base64_decode|gzinflate|str_rot13)" /var/www/审计所有用户的SSH authorized_keys文件:
find /home -name "authorized_keys" -exec grep -H "." {} ;在运行VPS with cPanel时,这些审计尤为重要,因为cPanel环境托管多个账户,一个账户被入侵可能影响其他账户。
大规模搜索的性能优化
限制搜索深度以避免不必要地遍历深层目录树:
find /var/www -maxdepth 3 -type f -name "*.php" -exec grep -l "eval(" {} ;对速度要求高的任务使用ripgrep。虽然本文不深入介绍,但由于并行处理和更智能的文件过滤,rg在大型代码库上比grep快3–10倍。它在大多数发行版的软件仓库中均可获取:
apt install ripgrep # Debian/Ubuntu
yum install ripgrep # CentOS/RHEL使用time分析搜索性能以对不同方法进行基准测试:
time grep -r "pattern" /large/directory/避免搜索/proc和/sys——这些虚拟文件系统可能导致挂起或产生无意义的输出:
grep -r --exclude-dir={proc,sys,dev} "pattern" /选择正确方法:决策矩阵
| 场景 | 推荐命令 | |
|---|---|---|
| 在目录中快速搜索关键词 | grep -rn "keyword" /path/ | |
| 不区分大小写的完整单词搜索 | grep -rniw "keyword" /path/ | |
| 仅搜索特定文件类型 | grep -r --include="*.conf" "keyword" /path/ | |
| 搜索最近修改的文件 | find /path -mtime -1 -exec grep -l "keyword" {} ; | |
| 高效搜索大型文件树 | `find /path -print0 | xargs -0 grep -l "keyword"` |
| 从日志中提取结构化数据 | awk '/pattern/ { print $1, $NF }' logfile | |
| 搜索压缩日志 | zgrep "keyword" /var/log/*.gz | |
| 实时日志监控 | `tail -f /var/log/file.log | grep –line-buffered "pattern"` |
| 敏感字符串安全审计 | grep -rPl "eval(base64_decode" /var/www/ |
关键技术要点
- 使用
grep -rniw作为默认递归搜索——它可在一次操作中处理大小写、完整单词和行号。 - 始终将
-print0与find配合使用,将-0与xargs配合使用,以安全处理包含空格或特殊字符的文件名。 - 使用
-exec grep ... {} +(加号而非分号)将多个文件批量传入单次grep调用,减少进程开销。 grep -R(大写R)跟随符号链接;grep -r不跟随——了解您的环境需要哪种行为。- 在脚本中于
grep之前设置LC_ALL=C,以避免与区域设置相关的性能损耗和编码意外。 - 使用
--include和--exclude-dir限制搜索范围,在模式匹配开始前排除不相关的文件。 - 对于通过VPS Control Panels管理的多账户托管环境,将这些命令作为cron任务定期执行内容审计,以自动化安全检查。
- 在Shared Web Hosting环境中,内容搜索权限可能受到托管服务商的限制——请仅在您自己账户的文件树范围内使用这些命令。
常见问题解答
在Linux服务器上搜索所有文件中的文本,最快的方法是什么?
对于大型文件树,使用带有文件类型限制的grep -r --include="*.ext" "pattern" /path/,或安装ripgrep(rg "pattern" /path/),它使用多线程,在大型代码库上通常比标准grep快3–10倍。
如何在文件中搜索字符串时排除某些目录?
使用grep的--exclude-dir选项:grep -r --exclude-dir={.git,node_modules,vendor} "pattern" /path/。对于基于find的搜索,在-exec子句之前使用-not -path "*/dirname/*"。
grep -r和grep -R有什么区别?
grep -r执行递归搜索但不跟随符号链接。grep -R执行相同的递归搜索并额外跟随符号链接。仅在确认目标目录树中不存在循环符号链接时才使用-R。
我能在不解压的情况下搜索压缩的.gz日志文件内容吗?
可以。对单个文件使用zgrep "pattern" /var/log/file.log.gz,对多个压缩文件使用zgrep "pattern" /var/log/*.gz。输出格式与标准grep完全相同。
如何在Linux文件中搜索多行模式?
标准grep逐行匹配,无法原生匹配跨越多行的模式。使用带有Perl兼容正则表达式和n换行符的grep -P,或在pcregrep可用时使用pcregrep -M "line1nline2" file。对于复杂的多行提取,重新定义RS(记录分隔符)的awk通常是可读性最佳的解决方案。


