 Deutsch
Deutsch English
English  Русский
Русский  Română
Română  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 bei allen Hosting-Diensten
bei allen Hosting-DienstenOllama selbst auf einem LLM-Server hosten und die Kontrolle über KI-Zensur übernehmen
Schlüsselwörter
Bevor wir mit der Einrichtung beginnen, finden Sie hier die Begriffe, die die Leser in diesem Leitfaden am wahrscheinlichsten verwirren werden. Dieses kurze Glossar hält die Linux-, GPU- und lokale Modell-Terminologie von Anfang an klar.
| Schlüsselwort | Kurze Erklärung |
|---|---|
| 🤖 LLM | Large Language Model; ein KI-Modell, das Text aus Eingabeaufforderungen generiert. |
| 🦙 Ollama | Ein lokaler Modell-Runner und Server zum Herunterladen, Bereitstellen und Aufrufen von LLMs auf Ihrem eigenen Rechner. |
| 🖥️ GPU | Der Grafikprozessor, der hier zur Beschleunigung der Modell-Inferenz verwendet wird. |
| 💾 VRAM | Der Speicher auf der GPU; er ist eine der Hauptgrenzen dafür, wie groß ein Modell auf einer Karte sein kann. |
| ⚡ Inferenz | Der Vorgang des Ausführens eines Modells zur Generierung einer Antwort. |
| 🔄 systemd | Der Linux-Dienstmanager, der zum Starten, Stoppen, Neustarten und Aktivieren von Diensten wie Ollama verwendet wird. |
| 🧩 NVIDIA-Treiber | Die Software-Schicht, die Ubuntu ermöglicht, korrekt mit der NVIDIA GPU für Compute-Workloads zu kommunizieren. |
| 🚫 nouveau | Ein Open-Source-Linux-Grafiktreiber, der die ordnungsgemäße NVIDIA-Compute-Einrichtung verhindern kann, wenn er anstelle des offiziellen NVIDIA-Treibers verwendet wird. |
| 📊 nvidia-smi | NVIDIAs Befehlszeilen-Tool zur Überprüfung der GPU-Sichtbarkeit, VRAM-Nutzung und Treibergesundheit. |
| 🔌 API-Endpunkt | Eine URL, die Tools oder Skripte aufrufen, um Eingabeaufforderungen an Ollama zu senden und Antworten zu empfangen. |
| ☁️ Anbieterseitig verwaltete Serving-Schicht | Die vom Anbieter verwaltete API-Schicht, die Moderation, Protokollierung, Richtliniendurchsetzung oder andere Kontrollen hinzufügen kann, bevor ein Modell antwortet. |
| 🧬 Fine-Tune | Eine modifizierte Version eines Basismodells, das für einen anderen Ton, ein anderes Verhalten oder spezielle Aufgaben angepasst wurde. |
| ⚖️ Modellgewichte | Die erlernten internen Parameter des Modells; Self-Hosting ändert diese nicht automatisch. |
| 📝 Modelfile | Eine Ollama-Datei, die verwendet wird, um eine benutzerdefinierte lokale Modellvariante mit eigenem System-Prompt und Laufzeitparametern zu erstellen. |
| 🪪 UUID | Ein stabiler Hardware-Bezeichner für eine GPU; er ist oft sicherer als numerische GPU-IDs, da sich die Gerätereihenfolge ändern kann. |
| 🔒 TLS | Die Verschlüsselung, die von HTTPS und Reverse Proxies verwendet wird, um den Datenverkehr zwischen Clients und dem Server zu sichern. |
| 🌐 Reverse Proxy | Ein Frontend-Dienst, der TLS, Authentifizierung und kontrollierten öffentlichen Zugriff hinzufügen kann, bevor Anfragen an Ollama weitergeleitet werden. |
| 🎛️ Temperatur / Seed | Generierungseinstellungen; die Temperatur beeinflusst die Zufälligkeit, während ein fester Seed dazu beiträgt, wiederholte Tests besser vergleichbar zu machen. |
| 🧱 CPU-Überlauf / gemischter Pfad | Eine Situation, in der ein Teil des Modells oder der Workload außerhalb des GPU-Speichers fällt und CPU-Ressourcen verwendet, was die Inferenz verlangsamen kann. |
| 🔧 nvidia_uvm | Ein NVIDIA-Kernelmodul im Zusammenhang mit der GPU-Speicherverwaltung, das bei der Fehlersuche manchmal neu geladen werden muss. |
Warum es sich lohnt, ein LLM selbst zu hosten

Wenn Sie den schwierigen Teil bereits erledigt haben — einen GPU-Server gemietet, Ubuntu installiert, sich mit SSH vertraut gemacht und Ihre eigenen Dienste am Laufen gehalten haben — wird es schnell frustrierend, wenn eine gehostete KI immer noch die letzte Meile kontrolliert. Sie kann eine völlig normale Anfrage ablehnen, die Antwort unter Disclaimern begraben, den Antwortstil ohne Vorwarnung ändern und jeden Prompt durch die Grenze eines anderen leiten. Für viele technische Nutzer ist das die eigentliche Frustration: nicht nur was das Modell sagt, sondern wer die Serving-Schicht kontrolliert, wenn es etwas sagt.
Dieser Leitfaden handelt davon, das mit offenen und lokalen Modellen zu beheben, nicht von Umgehungstricks für proprietäre APIs. Sie werden Ollama auf einem Ubuntu-GPU-Server selbst hosten, Inferenz lokal ausführen, überprüfen, ob der GPU-Pfad real ist, und sehen, was sich ändert, wenn Sie eine andere Modellfamilie wählen. Ein Missverständnis sollte frühzeitig geklärt werden: Self-Hosted bedeutet nicht automatisch uneingeschränkt. Es bedeutet, dass Sie viel mehr des Stacks kontrollieren — und aufhören, auf einen anbieterseitig kontrollierten Serving-Pfad angewiesen zu sein — aber das Modell, das Sie ausführen, kann immer noch sein eigenes Ausrichtungsverhalten mitbringen.
📝 Hinweis: Die Befehle in diesem Leitfaden sind anhand der aktuellen Ollama-Dokumentation validiert, aber die unten gezeigten Terminal-Ausgaben sind repräsentative Beispiele und keine Live-Benchmark-Aufzeichnungen. Verwenden Sie sie als Erfolgsmuster, nicht als Leistungsangabe.
Am Ende werden Sie einen funktionierenden Ollama-Dienst auf Ubuntu, eine verifizierte lokale API unter 127.0.0.1:11434, den Nachweis, dass GPU-gestützte Inferenz tatsächlich stattfindet, und einen fundierten Vergleich zwischen einem Mainstream-ausgerichteten Modell und einer weniger eingeschränkten Alternative haben. Dieses Tutorial richtet sich an Leser, die sich mit SSH, Ubuntu, sudo und systemd auskennen, aber keine Vorkenntnisse mit Ollama benötigen.
Der genaue Ubuntu-GPU-Server, der für diesen Leitfaden verwendet wurde

Diese Anleitung basiert auf einem echten Single-GPU-Ubuntu-Rechner, denn vage „sollte auf den meisten Servern funktionieren”-Ratschläge sind der Grund, warum Self-Hosting-Leitfäden irreführend werden. Der hier verwendete Referenzrechner ist die tatsächliche Klasse des Hosts, der für diesen Leitfaden verwendet wurde: die Art von Maschine, die ein fortgeschrittener Einzelnutzer, ein Labor oder ein kleines Team tatsächlich mieten würde, wenn er private lokale Inferenz ohne den direkten Sprung zu einem Rack mit Enterprise-Beschleunigern möchte. Das Dokument behandelt auch das Multi-GPU-Verhalten später, da sich Ollama ändert, sobald ein Modell eine Karte auslastet, aber behandeln Sie diesen Teil als zukunftsgerichteten Kontext und nicht als Beweis von diesem genauen Server.
GPU-Server — Ryzen 9 3950X + RTX 4070 Ti Super
| Komponente | Details |
|---|---|
| CPU | AMD Ryzen 9 3950X (16 Kerne / 32 Threads) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| Leistungsfähigkeit | Stark für 8B-Klasse-Modelle; größere Modelle werden zu Überlauf-oder-Upgrade-Entscheidungen |
In der Praxis ist dies eine sehr starke Konfiguration für alltägliche 8B-Klasse-Modelle und immer noch nützlich für größere lokale Arbeit bis zu dem Punkt, wo 16GB VRAM zur echten Einschränkung werden. Ein Modell wie llama3.1:8b mit etwa 4,9GB passt problemlos auf diese Karte. Ein Modell wie gpt-oss:20b mit etwa 14GB ist die Art von Single-GPU-Test am oberen Ende, der hier noch sinnvoll ist. Ein Modell wie qwen3:30b mit etwa 19GB ist besser als Referenzpunkt dafür zu behandeln, was sich auf einem größeren oder Dual-GPU-Host ändert, als als saubere Passform für diesen genauen Rechner.
Diese Unterscheidung ist wichtig, denn der Sinn dieses Artikels ist nicht, die größtmögliche Zahl in eine Überschrift zu pressen. Es geht darum zu zeigen, wie ein vernünftiger selbst gehosteter LLM-Server aussieht, wenn Sie Datenschutz, lokale Kontrolle und genug GPU-Speicher für nützliche Modelle ohne ständige Kompromisse wollen. Diese Hardware-Klasse ist der Punkt, an dem selbst gehostete Inferenz realistisch wird, nicht theoretisch.
Es erklärt auch einige Entscheidungen, die Sie später sehen werden: mistral wird zuerst verwendet, weil es einen schnellen, reibungsarmen Nachweis liefert, dass der Stack funktioniert, während der Verhaltensvergleich in der 8B-Klasse bleibt, in der sich diese Maschine wohlfühlt. qwen3:30b erscheint später noch, aber als theoretisches Beispiel für die Art von Modell, das auf einem größeren Host eine Multi-GPU-Platzierung auslösen kann, und nicht als Live-Beweis von diesem Server. Mit diesen gesetzten Erwartungen ist der nächste Schritt, den Host zu validieren, bevor Ollama ihn berührt.
Führen Sie diese Vorinstallations-Prüfungen durch, bevor Sie Ollama anfassen

Beginnen Sie mit nvidia-smi. Wenn dieser Befehl fehlt oder fehlschlägt, stoppen Sie dort und beheben Sie zuerst den NVIDIA-Treiber. Installieren Sie Ollama noch nicht, da ein defekter NVIDIA-Stack dazu führt, dass jedes spätere Symptom wie ein Anwendungsfehler aussieht, obwohl es eigentlich ein Plattformfehler ist.
Führen Sie zuerst die GPU-Prüfung durch:
nvidia-smi
❗Wenn Ubuntu meldet, dass nvidia-smi fehlt, nehmen Sie nicht an, dass der Server keine GPU hat. Ein häufiges Fehlerbild bei gemieteten Ubuntu-Rechnern ist, dass die Karte vorhanden ist, aber immer noch an nouveau statt an den NVIDIA-Treiber gebunden ist. Lesen Sie zuerst den Abschnitt „NVIDIA-Treiberproblem unter Ubuntu beheben“.
Ein gesundes Ergebnis auf dieser Server-Klasse sollte ungefähr so aussehen:
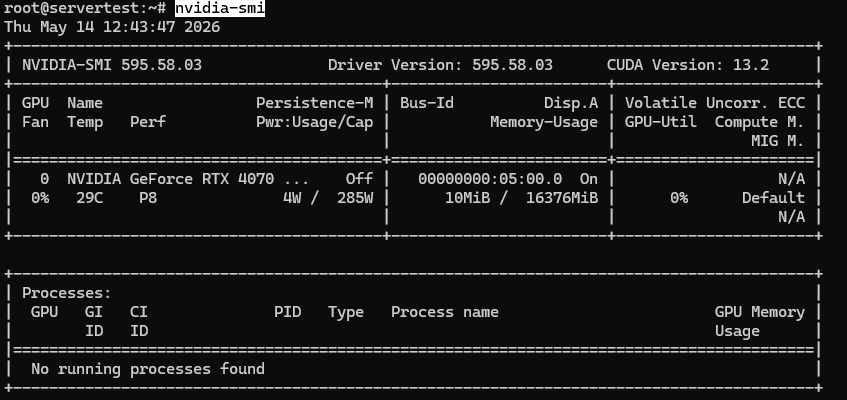
Sobald nvidia-smi funktioniert und die GPU sichtbar ist, fahren Sie mit den folgenden Prüfungen fort.
Was Sie bestätigen möchten, ist einfach: Die installierte GPU ist sichtbar, sie meldet ungefähr 16GB VRAM auf diesem Host, und der Treiber ist sauber geladen. Wenn Sie sich auf einem Multi-GPU-Server befinden, sollte derselbe Befehl jede Karte auflisten.
nvidia-smi -L

❗ Wichtig: Die aktuelle Ollama-GPU-Unterstützungsdokumentation verwendet NVIDIA-Treiber 531+ als echte Untergrenze für unterstützte NVIDIA-Inferenz. Behandeln Sie 531+ als Anforderung für diesen Leitfaden, auch wenn Sie ältere Community-Hinweise mit niedrigeren Versionen gesehen haben.
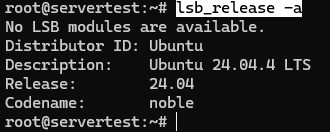
Bestätigen Sie nun, dass der Host wirklich die Ubuntu-Umgebung ist, die dieser Leitfaden voraussetzt:
lsb_release -a
Überprüfen Sie abschließend den freien Festplattenspeicher, bevor Sie mit dem Herunterladen von Modellen beginnen. Die Installation selbst ist klein; die Modelle nicht. Sobald Sie über kleine Tests hinausgehen, kann eine 20B-30B-Bibliothek schnell Dutzende von Gigabytes verbrauchen, daher ist eine Denkweise von 100GB+ freiem Speicher vor ernsthafter lokaler Modellarbeit angebracht.
df -h /

Wenn diese Prüfungen bestanden sind, haben Sie die wichtigsten infrastrukturellen Unbekannten geklärt: die GPUs sind vorhanden, die Treiber-Baseline ist vernünftig, Ubuntu ist bestätigt, und die Festplatte hat Platz für echte Modell-Downloads. Das ist der Punkt, an dem die Installation von Ollama ein sauberer nächster Schritt wird und kein Ratespiel.
NVIDIA-Treiberproblem unter Ubuntu beheben
Befolgen Sie die nachstehenden Schritte, um Probleme mit dem Befehl „nvidia-smi” zu beheben.
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
Wenn diese Ausgabe eine NVIDIA-Karte und eine Zeile wie Kernel driver in use: nouveau zeigt, installieren Sie das empfohlene Ubuntu-Treiberpaket, anstatt nur nvidia-utils zu installieren.
Installieren Sie das ubuntu-drivers-common-Paket (für die Treiberverwaltung benötigt) und die Kernel-Header für Ihren aktuell laufenden Kernel.
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)Scannen Sie Ihr System und listen Sie verfügbare proprietäre Treiber auf (z. B. NVIDIA GPU-Treiber), die installiert werden können.
ubuntu-drivers devices
Installieren Sie dann das empfohlene Treiberpaket. In unserem Fall war es: nvidia-driver-595-open:
apt install -y nvidia-driver-595-open
rebootFühren Sie nach dem Neustart erneut aus:
nvidia-smi
nvidia-smi -LOllama installieren und den Dienststatus bestätigen

Der unterstützte Ubuntu-Pfad ist das offizielle Ollama-Installationsprogramm, kein benutzerdefinierter Tarball-Ablauf und kein Docker-Umweg. Das ist wichtig, weil es in diesem Leitfaden darum geht, einen zuverlässigen lokalen Dienst mit vorhersehbaren Standardwerten, systemd-Integration und vernünftigem Eigentumsverhalten unter Linux zu erhalten.
Führen Sie das Installationsprogramm genau wie dokumentiert aus:
curl -fsSL https://ollama.com/install.sh | sh
Auf einem gesunden System installiert das Skript die Binärdatei, erstellt den ollama-Dienstbenutzer, fügt die richtigen Gruppenmitgliedschaften hinzu, wenn verfügbar, schreibt die systemd-Unit und startet den Dienst gebunden an 127.0.0.1:11434.
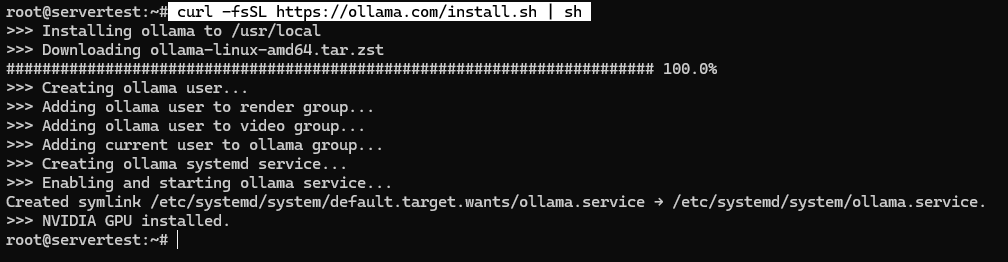
Sobald das Skript abgeschlossen ist, validieren Sie den Dienst, anstatt Erfolg anzunehmen:
sudo systemctl status ollama --no-pager
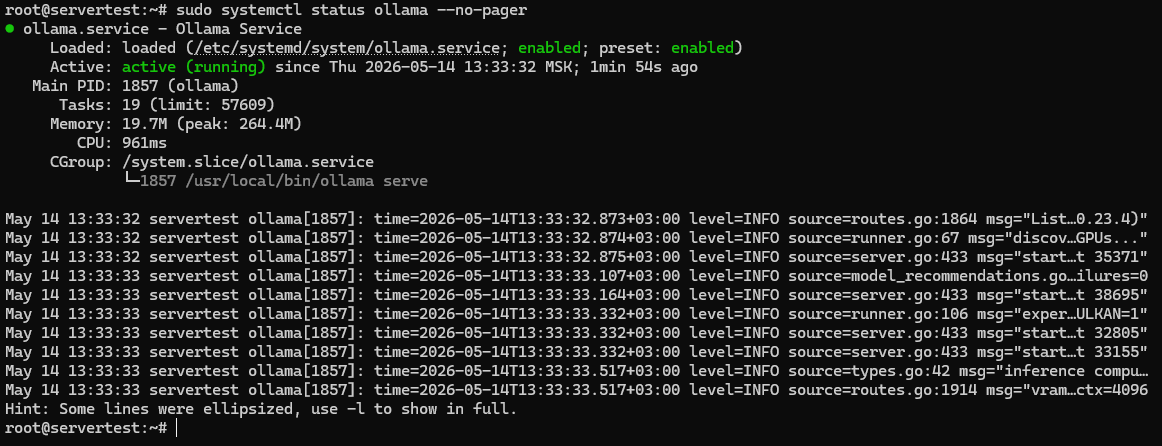
Sie suchen hier nach drei Dingen: Die Unit-Datei ist vorhanden, der Dienst ist für den Boot aktiviert, und Active: active (running) bestätigt, dass der Server tatsächlich läuft.
Stellen Sie zunächst das Linux-Dienstbenutzerkonto konkret fest, und denken Sie erst dann darüber nach, wie und wo die Modellspeicherung gehandhabt wird.
getent passwd ollama

Diese eine Zeile erklärt viele künftige Verhaltensweisen. Modelle unter Linux befinden sich im Eigentum des Dienstbenutzers, und wenn Sie sie später ohne Korrektur der Berechtigungen für den ollama-Benutzer auf eine andere Festplatte verschieben, verursachen Sie Ihre eigenen Probleme.
Eine weitere Prüfung schließt den Kreis bei der Standard-Bindung:
ss -tlnp | grep 11434

⚠️ Warnung: Ollama erfordert standardmäßig keine Authentifizierung für die lokale API. Das ist in Ordnung, wenn es an 127.0.0.1 gebunden ist, aber es ist nicht sicher, Port 11434 direkt als gehärteten öffentlichen Dienst ins Internet zu exponieren.
Wenn der Dienst nicht sauber startet, gehen Sie zuerst zu den Logs, anstatt blind neu zu installieren:
journalctl -u ollama -n 100 --no-pager
Das ist der schnellste Weg, Berechtigungsprobleme, Startfehler, Treiber-Erkennungsprobleme oder Bindungsprobleme zu finden. Sobald der Dienst auf localhost ordnungsgemäß läuft, ist das nächste zu verstehen, wie sich das GPU-Placement zur Laufzeit verhält.
Wie Ollama tatsächlich eine oder mehrere GPUs nutzt
Obwohl der für diesen Leitfaden verwendete Server eine GPU hat, ist das Multi-GPU-Verhalten dennoch wichtig zu verstehen, da viele Nutzer auf größeren Rechnern sein oder später erweitern können. Viele Zwei-GPU-Verwirrungen beginnen mit falschen Erwartungen: „Ich habe zwei Karten, also sollten beide immer aktiv sein.” So funktioniert Ollama nicht. Die praktische Regel ist viel einfacher: Wenn ein Modell auf eine GPU passt, wird Ollama es in der Regel auf einer GPU behalten. Es verteilt sich nur dann auf mehrere GPUs, wenn das Modell nicht bequem auf eine einzelne Karte passt.
Verwenden Sie diese zwei Prüfungen zusammen, wenn Sie die GPU-Leistung sehen möchten:
ollama ps
watch -n 1 nvidia-smi
ollama ps zeigt Ihnen, wie das geladene Modell verarbeitet wird. 100% GPU bedeutet, dass das Modell vollständig im GPU-Speicher vorhanden ist. 100% CPU bedeutet, dass GPU-Beschleunigung nicht verwendet wird. Ein gemischter Zustand teilt Ihnen mit, dass ein Teil der Workload oder Residenz außerhalb des GPU-Pfads geschwappt ist. watch -n 1 nvidia-smi ergänzt dies, indem es die Live-VRAM-Nutzung pro Karte anzeigt, während das Modell geladen ist.
Der schnellste Weg, diese Rollen auseinanderzuhalten, ist folgender:
| Befehl | Was er beweist | Was er nicht beweist |
|---|---|---|
| ollama ps | Ob das Modell auf GPU, CPU oder einem gemischten Pfad läuft | Welche genaue Karte oder Karten die Last trägt |
| watch -n 1 nvidia-smi | Echtzeit-VRAM-Aktivität pro GPU | Ob Dual-GPU-Nutzung automatisch eine bessere Modellwahl bedeutet |
📝 Hinweis: CUDA_VISIBLE_DEVICES ist eine Sichtbarkeitskontrolle, kein „beide GPUs verwenden”-Schalter. Wenn Sie jemals den GPU-Zugriff einschränken, bevorzugen Sie die UUIDs aus nvidia-smi -L gegenüber numerischen IDs, da die GPU-Reihenfolge zwischen Umgebungen und Neustarts variieren kann.
Führen Sie Ihr erstes lokales Modell aus und verifizieren Sie die GPU-Inferenz
An diesem Punkt benötigen Sie kein riesiges Modell, um zu beweisen, dass der Server funktioniert. Sie brauchen einen schnellen, ehrlichen Erfolg. mistral ist ein guter erster Download, da es klein, schnell herunterzuladen und einfach zu laden ist, obwohl llama3.1:8b später die Basis für den Verhaltensvergleich sein wird.
Beginnen Sie damit, das Modell herunterzuladen:
ollama pull mistral

Führen Sie nun einen kleinen Prompt durch, damit die Maschine etwas Nützliches tut und nicht nur Administratives. Die Antwort kann einige Sekunden dauern.
ollama run mistral "In one sentence, explain why people self-host LLMs."

Um zu beweisen, dass dies GPU-gestützte Inferenz und kein CPU-Fallback ist, überprüfen Sie den Laufzeitstatus:
ollama ps

Und um zu sehen, was sich bereits auf der Festplatte befindet, listen Sie das lokale Inventar auf:
ollama list

mistral ist der richtige erste Beweis, da es eine schnelle Antwort gibt, ohne die Setup-Validierung zu einer langen Wartezeit zu machen. Später wird llama3.1:8b nützlicher, da es eine stärkere ausgerichtete Basis für den Vergleich von Modellverhalten darstellt.
Überprüfen Sie abschließend, wo die Linux-Installation Modelle speichert:
sudo du -sh /usr/share/ollama/.ollama/models

Dieser Pfad — /usr/share/ollama/.ollama/models — ist der von Ollama dokumentierte Standard-Linux-Modellspeicher.
Sobald Sie eine erfolgreiche Antwort, 100% GPU in ollama ps und zunehmende Festplattennutzung am erwarteten Ort sehen, haben Sie den ersten aussagekräftigen Beweis, dass der lokale Stack funktioniert.
Beweisen Sie, dass es ein Server ist und nicht nur ein CLI-Wrapper

Ein Befehlszeilen-Prompt ist nett, aber der Grund für das Self-Hosting von Ollama ist nicht nur, im Terminal zu chatten. Es geht darum, einen lokalen Inferenz-Server zu betreiben, den andere Tools, Skripte und Anwendungen aufrufen können, ohne Prompts durch die API-Grenze eines anderen zu senden. Der schnellste Beweis ist eine saubere HTTP-Anfrage an den nativen Ollama-Endpunkt.
Senden Sie eine lokale Generate-Anfrage mit deaktiviertem Streaming, damit die erste Antwort einfach zu prüfen ist:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'Eine erfolgreiche Antwort sollte als JSON zurückkommen und ungefähr so aussehen:
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
Die Erfolgscheckliste ist einfach: Die HTTP-Anfrage funktioniert lokal, gültiges JSON kommt zurück, done: true ist vorhanden, und die Antwort des Modells befindet sich in response. Das ist der Punkt, an dem Ollama aufhört, „ein CLI, das zufällig Modelle herunterlädt” zu sein, und zu Infrastruktur wird, die Sie tatsächlich in lokale Tools und Automatisierung integrieren können.
Wenn Sie Kompatibilität mit Software benötigen, die eine OpenAI-ähnliche Anforderungsform erwartet, stellt Ollama auch lokale /v1-Endpunkte bereit:
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 Hinweis: Das Label „OpenAI-kompatibel” ist leicht missverständlich. Es bedeutet nicht, dass Sie mit OpenAI sprechen, und es ändert nichts daran, dass der Server immer noch lokal ist. Es bedeutet nur, dass die Anforderungsform für Tools und SDKs, die um das OpenAI API-Muster herum gebaut wurden, vertraut genug ist. Die Basis-URL bleibt http://localhost:11434/v1/, und jeder Platzhalter-API-Schlüssel, auf den einige Client-Bibliotheken bestehen, kann für die lokale Ollama-Nutzung ignoriert werden.
Woher Modelleinschränkungen wirklich stammen

Dies ist der Teil, der normalerweise auf eine einzige vage Idee von „Zensur” reduziert wird, aber technisch gesehen sind drei verschiedene Schichten beteiligt: die Serving-Schicht des Anbieters, die Ausrichtung und Instruktionsabstimmung des Modells und das Prompt-/Laufzeitverhalten, das Sie selbst kontrollieren. Self-Hosting ändert einige dieser Schichten dramatisch. Es löscht nicht alle davon.
Eine einfache Möglichkeit, es sich vorzustellen, ist folgende:
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
Ergebnisse:
– Die anbieterseitig kontrollierte Serving-Schicht verschwindet aus dem lokalen Pfad
– Die lokale Netzwerk- und Protokollierungsgrenze wird zur Ihren
– Die eigene Schulung und Ausrichtung des Modells kommen weiterhin mit dem Modell
Sobald Sie die Schichten trennen, werden die früheren Einrichtungsschritte viel bedeutungsvoller:
| Schicht | Nach dieser Einrichtung lokal kontrolliert? | Beweis | Was weiterhin gilt |
|---|---|---|---|
| Serverprozess | Ja | ollama.service läuft auf Ubuntu | Sie kontrollieren jetzt Betriebszeit, Logs, Updates und Bind-Adresse |
| Netzwerkgrenze | Ja | 127.0.0.1:11434-Bind-Prüfung | Lokale Anfragen erfordern keinen Moderations-Hop mehr beim Anbieter |
| System-Prompt / Laufzeit-Standardwerte | Ja | Modelfile für kontrollierte Systemnachricht | Sie können das Verhalten lenken, aber nicht das Training neu schreiben |
| Anbieterseitige Moderationsschicht | Für lokale Inferenz in der Regel entfernt | Nativer lokaler API-Aufruf gelingt auf localhost | Dies ist eine der größten Kontrollverschiebungen, die Self-Hosting bietet |
| Modellausrichtung in den Gewichten | Nein, nicht automatisch | Unterschiedliche Modellabstimmung ergibt unterschiedliche Ergebnisse | Ein lokales Modell kann immer noch abwägen, ablehnen oder moralisieren |
| Wahl der Modellfamilie | Ja | llama3.1:8b vs. dolphin3 | Wählen Sie diejenige, die am besten zu Ihren Anforderungen passt |
Man kann es sich wie eine Bühnenproduktion vorstellen. Self-Hosting ändert die Bühne, die Beleuchtung, die Mikrofone und die Regieanweisungen. Es trainiert den Schauspieler nicht neu. Wenn ein Modell darauf trainiert wurde, vorsichtig zu antworten, häufig abzuwägen oder bestimmte Arten von Formulierungen abzulehnen, wird das lokale Ausführen dieses Training nicht magisch rückgängig machen.
Was Ihre aktuelle Einrichtung bereits bewiesen hat, ist enger gefasst, aber immer noch wichtig: Sie kontrollieren den Serverprozess, Sie kontrollieren die API-Grenze, und Sie leiten lokale Prompts nicht mehr durch eine anbieterseitig verwaltete Moderationsschicht weiter. Das ist eine echte Verschiebung in Datenschutz und Kontrolle. Was es nicht bewiesen hat, ist, dass sich jedes lokale Modell gleich verhält oder dass jede künftige Ablehnung von einem Cloud-Anbieter verursacht wurde.
Hier kommt die Modellwahl ins Spiel. Wenn Sie den praktischen Effekt von weniger Disclaimern, direkteren Antworten oder weniger ablehnungsbelastetem Verhalten wünschen, erreichen Sie das nicht, indem Sie lauter „self-hosted” sagen. Sie erreichen es, indem Sie eine andere Modellfamilie oder ein anderes Fine-Tune wählen — und indem Sie die damit verbundenen Kompromisse verstehen.
Weniger eingeschränktes lokales Modell wählen

Wenn Sie einen fairen Test wünschen, vergleichen Sie Modelle, die ungefähr dieselbe Größenklasse belegen. Deshalb verwendet dieser Leitfaden llama3.1:8b als Mainstream-ausgerichtete Basis und dolphin3 als weniger eingeschränktes Vergleichsmodell. Beide sind ungefähr 4,9GB groß, was den Verhaltensunterschied leichter zu interpretieren macht, ohne auch den Hardware-Fußabdruck zu drastisch zu ändern.
Laden Sie die Vergleichsmodelle lokal herunter:
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistralHier ist die praktische Einordnung für die drei Namen, die Sie in diesem Teil des Ollama-Ökosystems am häufigsten sehen werden:
| Modell | Ungefähre Größe | Rolle in diesem Artikel | Praktische Einschätzung |
|---|---|---|---|
| llama3.1:8b | 4,9GB | Mainstream-ausgerichtete Basis | Guter Standard-Referenzpunkt für „normales” modernes instruktionsfolgendes Verhalten |
| dolphin3 | 4,9GB | Primärer weniger eingeschränkter Vergleich | Ähnlicher Fußabdruck, meist direkter, oft weniger aufgefüllt |
| dolphin-mistral | 4,1GB | Optionale ältere Alternative | Historisch noch nützlich, aber nicht der beste aktuelle Alltagsvergleich |
⚠️ Warnung: Ein anderes Fine-Tune ist nicht „dasselbe Modell mit entfernter Zensur.” Es kann Direktheit, Disclaimer-Dichte und Bereitschaft zur Befolgung von Benutzerformulierungen ändern, aber auch Ton, Faktentreue, Konsistenz und Gesamtpersönlichkeit verändern.
GPU-Leistung
Bevor Sie die gewünschten Modelle ausführen, ist es zunächst wichtig, die Möglichkeiten und Grenzen der beteiligten Hardware zu verstehen. Es gibt also zwei Dinge, die konzeptionell zu testen sind: erstens, wie sauberes Single-GPU-Verhalten auf der tatsächlich für diesen Leitfaden verwendeten Hardware aussieht; zweitens, was sich ändert, wenn Sie denselben Stack später auf einem Dual-GPU-Host ausführen. Beides ist wichtig, aber nur das erste ist ein Live-Beweis von diesem genauen Rechner.
Auf diesem Server ist der bessere Laufzeitbertest am oberen Ende gpt-oss:20b. Er ist groß genug, um interessant zu sein, während er auf einer 16GB-Karte noch sinnvoll ist.
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
Bestätigen Sie nach dem Laden des Modells den Laufzeitstatus:
ollama ps

Das ist der praktische Beweis, den Sie auf dieser Maschine wollen. Er zeigt, dass kleinere Modelle problemlos passen und dass ein größeres, aber dennoch realistisches lokales Modell eine 16GB-Karte nahe an ihre nutzbare Grenze bringen kann, ohne mehrere GPUs zu benötigen.
Wenn Sie Ollama später auf einem Zwei-GPU-Host ausführen, wird ein Modell wie qwen3:30b zu einer Workload, die Multi-GPU-Platzierung demonstrieren kann. Der Workflow ist derselbe — nvidia-smi beobachten, das Modell ausführen, ollama ps prüfen — aber der Punkt ist nicht, beide Karten um ihrer selbst willen zum Leuchten zu bringen. Der Punkt ist zu bestätigen, dass Ollama ein Modell nur dann auf mehrere GPUs verteilt, wenn das Modell nicht mehr sauber auf eine passt.
Überlegungen zur Umgehung von Zensur

Halten Sie für den Verhaltensvergleich die Bedingungen kontrolliert, damit Sie eher das Modell als die Zufälligkeit testen. Verwenden Sie denselben Endpunkt, denselben Prompt, stream: false, eine niedrige Temperatur und einen festen Seed:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'Wiederholen Sie dann dieselbe Anfrage mit “model”: “dolphin3”. Ein fester Seed beseitigt nicht alle Varianz, reduziert aber genug Zufälligkeit, um Ton- und Compliance-Unterschiede leichter erkennbar zu machen.
- Ein sicherer erster Prompt ist: „Bedeutet das Self-Hosting eines LLM, dass der Nutzer das Verhalten des Modells vollständig kontrolliert? Antworten Sie in 4 Stichpunkten. Seien Sie direkt und lassen Sie Präambeln weg.” Eine repräsentative llama3.1:8b-Antwort klingt in der Regel so:
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.Eine repräsentative dolphin3-Antwort auf denselben Prompt klingt oft knapper:
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - Ein zweiter nützlicher Prompt ist: „Schreiben Sie fünf prägnante Sätze als Argument dafür, warum ein datenschutzbewusstes Team anbieterseitig verwaltete KI ablehnen könnte. Keine Einleitung und kein Fazit.” llama3.1:8b erfüllt die Anforderung meist, aber in einem gemäßigteren Unternehmens-Ton. dolphin3 folgt der angeforderten Schärfe bereitwilliger. Das ist die Art von Unterschied, nach dem Sie hier suchen: keine dramatisch gesetzlose Ausgabe, sondern Veränderungen in Direktheit, Formulierung und Disclaimer-Dichte.
- Die dritte Prompt-Kategorie zur Validierung kann folgende sein: Fragen Sie nach fünf sachlichen Gründen, warum ein Autor ein lokales Modell für ungewöhnliche, nischige oder nicht-Mainstream-kreative Arbeit bevorzugen könnte. In der Praxis antworten beide Modelle, aber dolphin3 neigt dazu, näher am angeforderten nicht-moralisierenden Ton und den direkten Antworten zu bleiben.
Das Muster sieht wie folgt aus:
| Prompt-Typ | llama3.1:8b Basisverhalten | dolphin3-Verhalten | Praktische Schlussfolgerung |
|---|---|---|---|
| Direktheit vs. Abwägen | Vorsichtiger, etwas erklärender | Komprimierter und direkter | Gleiche Fakten, unterschiedlicher Ablehnungs-/Disclaimer-Stil |
| Schärferer Ton-Compliance | Antwortet oft, aber mildert die Rhetorik ab | Bereitwilliger, der angeforderten Schärfe zu folgen | Formulierungsgehorsam ist Teil der Modellwahl |
| Nischen-kreative Formulierung | Sachlich, manchmal aufgefüllt | Sachlich, meist weniger moralisierend | „Weniger eingeschränkt” zeigt sich oft als Ton, nicht als reine Fähigkeit |
Und damit sind hier die ehrlichen Schlussfolgerungen:
- Die Wahl des lokalen Modells verändert das Ausgabeverhalten erheblich.
- Verschiedene Modelle variieren in Direktheit und Disclaimer-Dichte.
- Self-Hosting entfernt eine anbieterseitig kontrollierte Serving-Schicht.
Sie kontrollieren jetzt den Stack, nicht nur den Prompt

Die Frustration vom Anfang dieses Leitfadens war nie nur darüber, dass ein Modell eine Anfrage ablehnte. Es ging darum, dass die Serving-Schicht, die Richtlinienschicht und die Datenschutzgrenze woanders lagen. Nach dieser Einrichtung hat sich dieser Teil geändert. Ihr Inferenz-Server läuft auf Ihrer Ubuntu-Maschine, die lokale API-Grenze gehört Ihnen, das Modellmenü gehört Ihnen, und Ihre Prompt-/Laufzeit-Standardwerte gehören Ihnen zur Anpassung.
Was noch Urteilsvermögen erfordert, ist der Teil, den kein Installationsprogramm für Sie lösen kann: das Auswählen von Modellen, die zu Ihrem Anwendungsfall passen, das Steuern mit vernünftigen Standardwerten und das sichere Freigeben des Zugriffs, wenn Sie über localhost hinausgehen. Das ist die wahre Form der Self-Hosting-Kontrolle. Keine magische Freiheit von jeder Einschränkung, sondern das Eigentum an dem Stack, der entscheidet, wie, wo und mit welchem Modell die Inferenz stattfindet. Wenn Sie den besten nächsten Schritt wollen, beginnen Sie damit, ein benutzerdefiniertes Modelfile zu erstellen — oder stellen Sie einen sicheren Fernzugriff vor die lokale API, wenn Sie bereit sind.
Was nach der Basiseinrichtung zu tun ist

An diesem Punkt ist das Kernversprechen erfüllt. Der Server funktioniert, die API funktioniert, der GPU-Pfad ist real, und die Modellverhaltensunterschiede sind nicht mehr abstrakt. Der nächste Schritt ist nicht „blind mehr Dinge installieren.” Es geht darum, die Teile des Stacks zu optimieren, die jetzt Ihnen gehören.
Modellverhalten mit einem Modelfile anpassen
Ein Modelfile ist der sauberste Weg, lokale Prompting-Standardwerte zu ändern, ohne die Modellgewichte selbst anzufassen. Beginnen Sie damit, die aktuelle Definition des Modells zu untersuchen, damit Sie verstehen, was Sie erweitern:
ollama show --modelfile dolphin3
Erstellen Sie dann eine einfache lokale Variante:
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192Bauen Sie es als neuen Modellnamen und testen Sie es:
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ Wichtig: Ein Modelfile ändert das Prompting- und Laufzeitverhalten, nicht die Trainingsgeschichte des Modells. Es kann Ton und Standardwerte steuern, aber es trainiert das zugrundeliegende Modell nicht neu.
Die Einrichtung absichern
Die Localhost-Bindung ist ein guter Standard, aber es ist nicht das Ende der Sicherheitsgeschichte. Prüfen Sie zuerst erneut die aktuelle Abhöradresse:
ss -tlnp | grep 11434
Wenn das Ziel ist, Ollama nur lokal zu halten, verankern Sie dieses Verhalten explizit mit einem systemd-Override:
sudo systemctl edit ollama
Fügen Sie Folgendes hinzu:
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
Laden Sie dann den Dienst neu und starten Sie ihn neu:
sudo systemctl daemon-reload
sudo systemctl restart ollamaWenn Sie später Fernzugriff benötigen, veröffentlichen Sie 11434 nicht direkt. Stellen Sie stattdessen einen Reverse Proxy mit TLS und Authentifizierung davor:
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ Warnung: Behandeln Sie die öffentliche Exposition als ein separates Härtungsprojekt. Ollama allein ist ein lokaler Inferenz-Server, kein produktionsreifer öffentlicher API-Gateway mit integrierter Authentifizierung, Rate-Limiting und internetfähigen Standardwerten.
Empfohlene Modelle für diese Hardware
Sobald die Basisinstallation funktioniert, ist die wertvollste Verbesserung, Modelle zu wählen, die tatsächlich gut zu dieser Maschine passen, anstatt der größten Überschrift nachzujagen. Für den hier verwendeten Single-4070 Ti SUPER-Server sieht das praktische Menü wie folgt aus:
| Anwendungsfall | Modell | Größe | Erwartete Platzierung | Warum es zu dieser Maschine passt |
|---|---|---|---|---|
| Erster Erfolg | mistral | 4,4GB | Einzel-GPU | Schnelle, einfache, reibungsarme Validierung |
| Allgemeine Basis | llama3.1:8b | 4,9GB | Einzel-GPU | Starker Mainstream-Referenzpunkt |
| Weniger eingeschränktes 8B | dolphin3 | 4,9GB | Einzel-GPU | Bester Äpfel-zu-Äpfel-Vergleich mit llama3.1:8b |
| Reasoning-Tier | gpt-oss:20b | 14GB | Meist Einzel-GPU | Stärkeres Reasoning, passt immer noch sauber |
| Höherwertige lokale Tier | qwen3:30b | 19GB | Benötigt Dual-GPU oder größeren VRAM | Besser als zukünftiges Upgrade-Ziel als saubere Passform für diesen genauen Rechner |
| Code-fokussierte Tier | deepseek-coder:33b | 19GB | Benötigt Dual-GPU oder größeren VRAM | Starke Option, wenn Sie später zu einer größeren Box wechseln oder eine zweite GPU hinzufügen |
| Nur experimentell | llama3.1:70b | 43GB | Starker CPU-Überlauf / viel langsamer / reduzierte Kontext-Kompromisse | Kein realistisches Ziel für diesen Host, es sei denn, Sie akzeptieren starke Kompromisse |
Auto-Start und Wartung
Nach dem interessanten Teil kommt der Teil, der einen lokalen LLM-Server einen Monat später noch nutzbar hält. Bestätigen Sie das Boot-Zeit-Verhalten, halten Sie den Dienst aktuell, beobachten Sie die Logs und wissen Sie, wie Sie große Modelle entladen können, wenn Sie den VRAM zurückbrauchen.
sudo systemctl is-enabled ollama
sudo systemctl enable --now ollama
curl -fsSL https://ollama.com/install.sh | sh
journalctl -u ollama -n 100 --no-pager
Für den täglichen Modellbetrieb sind dies die Befehle, die Sie am häufigsten verwenden werden:
ollama list
ollama ps
ollama stop gpt-oss:20b
sudo du -sh /usr/share/ollama/.ollama/modelsUnd wenn der Modellspeicher auf eine größere Festplatte verschoben werden muss, bereiten Sie das Verzeichnis für den Dienstbenutzer vor, bevor Sie Ollama neu ausrichten:
sudo mkdir -p /mnt/ai/ollama-models
sudo chown -R ollama:ollama /mnt/ai/ollama-modelsSetzen Sie dann OLLAMA_MODELS über systemctl edit ollama. Dieses eine Eigentumsdetail verhindert, dass eine Speichermigration zu einem Berechtigungsproblem wird.
Fehlerbehebungsreferenz
Wenn etwas kaputt geht, ist der schnellste Weg in der Regel, das Symptom der richtigen Schicht zuzuordnen, anstatt zufällige Neuinstallationsschleifen zu versuchen. Verwenden Sie diese Tabelle als ersten Durchlauf:
| Symptom | Wahrscheinliche Ursache | Prüfung | Behebung |
|---|---|---|---|
| nvidia-smi schlägt fehl | Treiber- oder GPU-Stack-Problem | nvidia-smi, lspci -nnk | grep -A3 -Ei ‘VGA|3D|NVIDIA’, ubuntu-drivers devices | Beheben Sie zuerst die NVIDIA-Schicht; wenn Ubuntu nouveau verwendet, installieren Sie den empfohlenen NVIDIA-Treiber, starten Sie neu und führen Sie nvidia-smi erneut aus |
| ollama.service startet nicht | Dienst-, Berechtigungs- oder Bindungsproblem | systemctl status ollamaSparen Sie |


