Türkçe
Türkçe English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 







Linux’ta Redis’te Tarama Komutlarını Kullanma
Açık kaynaklı, bellek içi bir veri yapısı deposu olan Redis, anahtar-değer veritabanı olarak hızı ve çok yönlülüğü ile bilinir. Güçlü özelliklerinden biri, tarama komutlarını kullanarak veri kümeleri arasında artımlı olarak yineleme yapabilmesidir. Bu özellikle büyük veri kümeleri ile çalışırken kullanışlıdır, çünkü sunucuyu zorlamadan verimli veri alımına izin verir. Özel bir Linux sunucusundaki kullanıcılar için Redis’te tarama komutlarını kullanmak, hassas, kaynak optimizasyonlu veri kümesi işlemeye izin vererek veri işleme performansını artırabilir. Bu makalede, Redis’te tarama komutlarının bir Linux ortamında nasıl etkili bir şekilde kullanılacağını keşfedeceğiz ve verileri büyük ölçekte yönetmek ve almak için ayrıntılı örnekler ve en iyi uygulamaları sunacağız
Tarama Komutları Nedir?
Redis’teki tarama komutları, anahtarlar, kümeler, hash’ler ve sıralanmış kümeler üzerinde bloklama olmadan yineleme yapmanın bir yolunu sağlar. Tüm eşleşen anahtarları bir kerede döndürdüğü için büyük veri kümeleri için tehlikeli olabilen KEYS komutunun aksine, tarama komutları bir seferde az sayıda öğe döndürür. Bu, performans etkisini en aza indirir ve artımlı yinelemeye olanak tanır
Anahtar Tarama Komutları
- SCAN: Anahtar uzayında anahtarlar arasında yineleme yapar.
- SSCAN: Bir kümedeki öğeler arasında yineleme yapar.
- HSCAN: Bir hash içindeki alanlar ve değerler arasında yineleme yapar.
- ZSCAN: Sıralanmış bir kümedeki üyeler ve puanlar arasında yineleme yapar.
Tarama Komutlarının Temel Sözdizimi
Her tarama komutu benzer bir sözdizimine sahiptir
- imleç: Taramaya başlanacak konumu temsil eden bir tamsayı. Yeni bir tarama başlatmak için 0 kullanın.
- MATCH pattern: (isteğe bağlı) Döndürülen anahtarları filtrelemek için bir kalıp. Glob tarzı kalıpları destekler.
- COUNT count: (isteğe bağlı) Redis’e her yinelemede kaç öğe döndürüleceği hakkında bir ipucu.
Linux üzerinde Redis Kurulumu
CentOS/RHEL için kullanın
Kurulduktan sonra Redis sunucusunu başlatın
Redis’e Bağlanma
Terminalinizi açın ve Redis CLI kullanarak Redis örneğinize bağlanın
Artık Redis komutlarını CLI’da çalıştırabilirsiniz
SCAN Komutunun Kullanılması
Örnek 1: Temel TARAMA
Redis veritabanındaki tüm anahtarları almak için kullanabilirsiniz
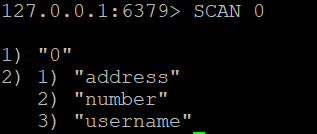
Bu komut bir imleç ve tuş listesi döndürecektir
Örnek 2: Tuşları Filtrelemek için MATCH Kullanımı
“user:” ile başlayan anahtarlar gibi belirli bir kalıpla eşleşen anahtarları bulmak istiyorsanız, şunu kullanabilirsiniz
Bu komut yalnızca “user:” ile başlayan anahtarları döndürür
Örnek 3: COUNT Belirtme
Redis’in her yinelemede kaç anahtar döndürmesi gerektiğini belirtmek için bir sayı belirtebilirsiniz
Bu, yaklaşık 10 anahtar döndürmeye çalışacaktır. Döndürülen gerçek sayının bundan daha az olabileceğini unutmayın
Örnek 4: Tüm Anahtarlar Arasında Yineleme
Birden fazla yinelemede tüm tuşlar arasında yineleme yapmak için, döndürülen imleci izlemeniz gerekir. İşte basit bir kabuk betiği örneği:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Process the result as needed
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Update the cursor
if [[ "$cursor" == "0" ]]; then
break # Stop when the cursor is back to 0
fi
doneSSCAN Komutunun Kullanılması
SSCAN komutu, bir kümedeki öğeler arasında yineleme yapmak için kullanılır. Sözdizimi SCAN’a benzer
SSCAN örneği
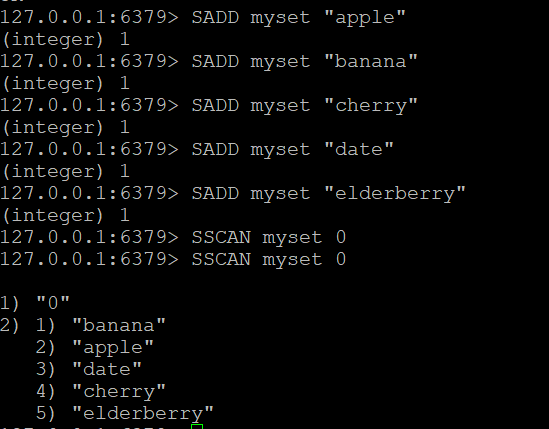
Adım 1: Bir Set Oluşturun ve Elemanları Ekleyin
Myset adında bir küme oluşturalım ve buna bazı öğeler ekleyelim
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"Adım 2: SSCAN Komutunu Kullanın
Artık myset adında bir kümemiz olduğuna göre, elemanları arasında yineleme yapmak için SSCAN komutunu kullanabiliriz
- Temel SSCAN Komutu: “myset” adında bir kümeniz olduğunu varsayalım. Öğelerini taramak için###ATP_PRO_NOTR_12_CODE_TAG_NOTR_ATP_PRO##
- MATCH Kullanımı: Bir kümedeki öğeleri bir kalıba göre filtrelemek ve “mango” kelimesini ve diğer varyasyonları içeren bazı öğeler eklemek için:###ATP_PRO_NOTR_13_CODE_TAG_NOTR_ATP_PRO##

- Bir Küme İçindeYineleme:Bir küme içinde yineleme yapmak için bir döngü kullanabilirsiniz:
#!/bin/bash
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor)
# Print the elements returned by SSCAN
echo "$result"
# Update the cursor for the next iteration
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Break the loop if cursor is back to 0
if [[ "$cursor" == "0" ]]; then
break
fi
doneKomut Dosyasını Çalıştırma
- Komut dosyasını scan_myset.sh olarak kaydedin.
- Çalıştırılabilir hale getirin
- Komut dosyasını çalıştırın
./scan_myset.sh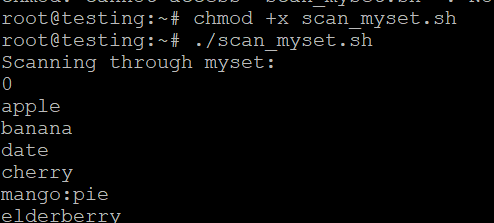
HSCAN ve ZSCAN Komutlarını Kullanma
HSCAN Komutu
HSCAN komutu, bir karma içindeki alanlar ve değerler arasında yineleme yapar
HSCAN komutu, bir hash içindeki alanlar ve değerler arasında yineleme yapmak için kullanılır
Adım 1: Bir Hash Oluşturun ve Alanlar Ekleyin
- Myhash adında bir hash oluşturun ve buna bazı alanlar ekleyin:
Adım 2: Karmayı Yinelemek için HSCAN’ı Kullanın
- Myhash içindeki alanlar arasında yineleme yapmak için HSCAN komutunu kullanın:
HSCAN myhash 0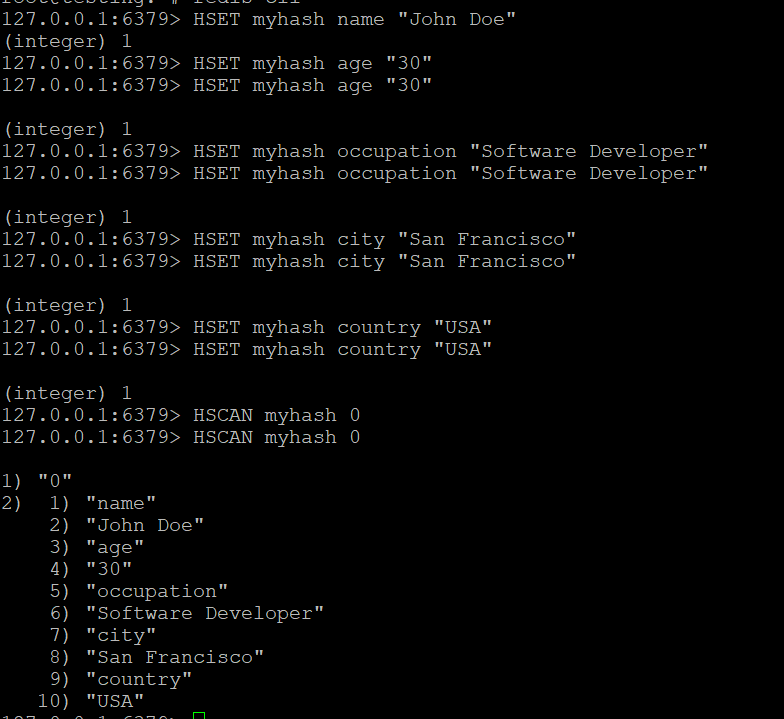
ZSCAN Komutu
ZSCAN, sıralanmış bir kümenin üyelerini artımlı olarak yinelemek için kullanılan bir Redis komutudur. Üyeleri, ilişkili puanlarıyla birlikte verimli ve engellemesiz bir şekilde almanıza olanak tanır. Bu komut, özellikle tüm üyeleri bir kerede getirmenin pratik olmayabileceği büyük sıralanmış kümelerle çalışmak için kullanışlıdır. ZSCAN komutu, sıralanmış bir kümedeki üyeler ve puanlar arasında yineleme yapar
Adım 1: Sıralanmış Küme Oluşturma ve Üye Ekleme
Mysortedset adında bir sıralanmış küme oluşturalım ve puanları olan bazı üyeler ekleyelim
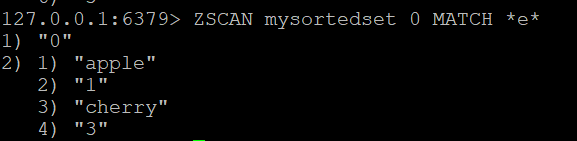
Temel ZSCAN Komutu:Sıralanmış seti taramaya başlamak için şunu kullanın
ZSCAN mysortedset 0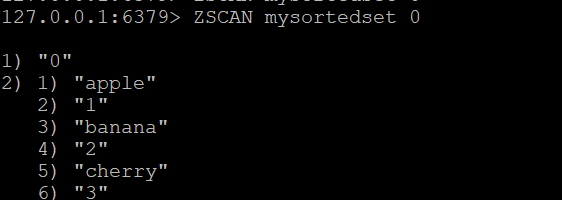
Adım 2: Üyeleri Filtrelemek için MATCH Kullanma (İsteğe Bağlı)
ZSCAN tarafından döndürülen üyeleri filtrelemek istiyorsanız, MATCH seçeneğini kullanabilirsiniz. Örneğin, “e” harfi içeren üyeleri bulmak için çalıştırabilirsiniz
ZSCAN mysortedset 0 MATCH *e*