Português
Português English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 







Usando os comandos de verificação no Redis no Linux
O Redis, um armazenamento de estrutura de dados em memória de código aberto, é conhecido por sua velocidade e versatilidade como um banco de dados de valor-chave. Um de seus recursos poderosos é a capacidade de iterar incrementalmente através de conjuntos de dados usando comandos de varredura. Isto é particularmente útil quando se lida com grandes conjuntos de dados, uma vez que permite a recuperação eficiente de dados sem sobrecarregar o servidor. Para usuários em um servidor Linux dedicado, o uso de comandos de varredura no Redis pode melhorar o desempenho do manuseio de dados, permitindo o processamento preciso e otimizado de recursos do conjunto de dados. Neste artigo, exploraremos como usar efetivamente os comandos de varredura no Redis em um ambiente Linux, oferecendo exemplos detalhados e práticas recomendadas para gerenciar e recuperar dados em escala..
O que são comandos de varredura?
Os comandos de varredura no Redis fornecem uma maneira de iterar sobre chaves, conjuntos, hashes e conjuntos ordenados de maneira não bloqueante. Ao contrário do comando KEYS, que pode ser perigoso para grandes conjuntos de dados porque retorna todas as chaves correspondentes de uma só vez, os comandos de varredura retornam um pequeno número de elementos por vez. Isto minimiza o impacto no desempenho e permite uma iteração incremental
Comandos de pesquisa de chaves
- SCAN: Itera através das chaves no espaço de chaves.
- SSCAN: Itera através de elementos num conjunto.
- HSCAN: itera através de campos e valores em um hash.
- ZSCAN: Itera através de membros e pontuações num conjunto ordenado.
Sintaxe básica dos comandos de pesquisa
Cada comando de verificação tem uma sintaxe semelhante
- cursor: Um número inteiro que representa a posição a partir da qual se inicia o varrimento. Para iniciar uma nova pesquisa, utilize 0.
- MATCH pattern: (opcional) Um padrão para filtrar as chaves retornadas. Suporta padrões do tipo glob.
- COUNT count: (opcional) Uma dica para o Redis sobre quantos elementos retornar em cada iteração.
Instalando o Redis no Linux
Para CentOS/RHEL, use
Uma vez instalado, inicie o servidor Redis
Conectando-se ao Redis
Abra seu terminal e conecte-se à sua instância Redis usando o Redis CLI
Agora é possível executar comandos do Redis na CLI
Usando o comando SCAN
Exemplo 1: SCAN básico
Para recuperar todas as chaves no banco de dados do Redis, você pode usar
SCAN 0#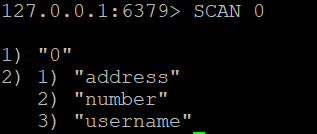
Esse comando retornará um cursor e uma lista de chaves
Exemplo 2: Utilizar MATCH para filtrar chaves
Se quiser encontrar chaves que correspondam a um padrão específico, como chaves que começam com “user:”, pode usar
Este comando devolve apenas as chaves que começam com “user:”
Exemplo 3: Especificando COUNT
Para indicar quantas chaves o Redis deve retornar em cada iteração, é possível especificar uma contagem
Isso tentará retornar aproximadamente 10 chaves. Note que o número real retornado pode ser menor que isso
Exemplo 4: Iterando por todas as chaves
Para iterar através de todas as chaves em múltiplas iterações, você precisa manter o controle do cursor retornado. Aqui está um exemplo simples de script de shell:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Process the result as needed
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Update the cursor
if [[ "$cursor" == "0" ]]; then
break # Stop when the cursor is back to 0
fi
doneUsando o comando SSCAN
O comando SSCAN é utilizado para iterar através dos elementos de um conjunto. A sua sintaxe é semelhante à do SCAN
Exemplo de SSCAN
Passo 1: Criar um conjunto e adicionar elementos
Vamos criar um conjunto chamado myset e adicionar-lhe alguns elementos
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"Etapa 2: usar o comando SSCAN
Agora que temos um conjunto chamado myset, podemos usar o comando SSCAN para iterar através de seus elementos
- Comando SSCAN básico: Suponha que você tenha um conjunto chamado “myset”. Para percorrer os seus elementos
SSCAN myset 0#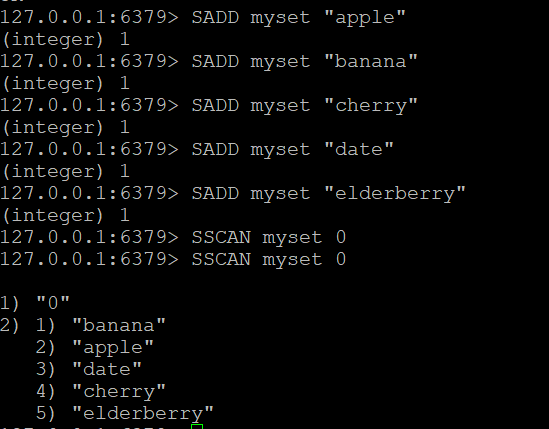
- Utilizar MATCH: Para filtrar os elementos de um conjunto com base num padrão e adicionar alguns elementos que incluem a palavra “manga” e outras variações:
SSCAN myset 0 MATCH mango:*#
- Iterar através de um conjunto:Pode utilizar um loop para iterar através de um conjunto:
#!/bin/bash
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor)
# Print the elements returned by SSCAN
echo "$result"
# Update the cursor for the next iteration
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Break the loop if cursor is back to 0
if [[ "$cursor" == "0" ]]; then
break
fi
doneExecutar o script
- Salve o script como scan_myset.sh.
- Torná-lo executável
- Executar o script
./scan_myset.sh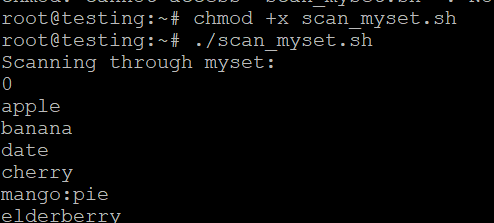
Utilizar os comandos HSCAN e ZSCAN
Comando HSCAN
O comando HSCAN itera através de campos e valores num hash
O comando HSCAN é utilizado para iterar através de campos e valores num hash
Etapa 1: criar um hash e adicionar campos
- Crie um hash chamado myhash e adicione alguns campos a ele:
Etapa 2: usar o HSCAN para iterar pelo hash
- Use o comando HSCAN para iterar pelos campos em myhash:
HSCAN myhash 0#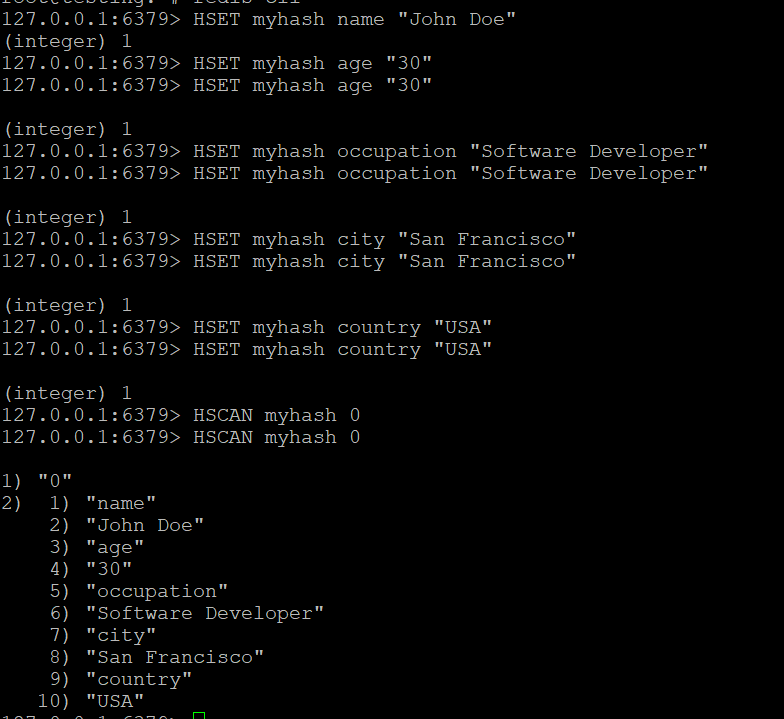
Comando ZSCAN
ZSCAN é um comando Redis usado para iterar através dos membros de um conjunto ordenado de forma incremental. Ele permite que você recupere membros junto com suas pontuações associadas de uma forma eficiente e sem bloqueio. Este comando é particularmente útil para trabalhar com grandes conjuntos ordenados onde buscar todos os membros de uma vez pode não ser prático. O comando ZSCAN itera através de membros e pontuações em um conjunto ordenado
Etapa 1: Criar um conjunto ordenado e adicionar membros
Vamos criar um conjunto ordenado chamado mysortedset e adicionar alguns membros com pontuações
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"Comando ZSCAN básico:Para começar a analisar o conjunto ordenado, use
ZSCAN mysortedset 0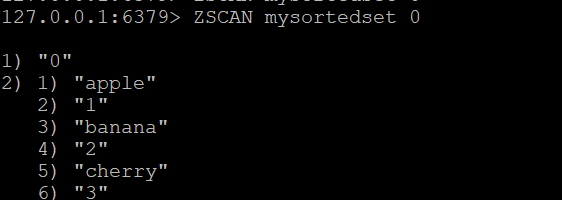
Etapa 2: Usando MATCH para filtrar membros (opcional)
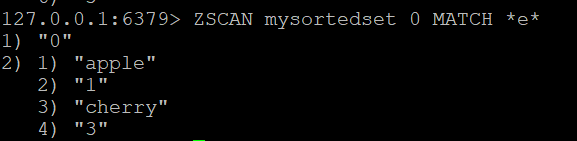
Se pretender filtrar as barras devolvidas pelo ZSCAN, pode utilizar a opção MATCH. Por exemplo, para encontrar membros que contenham a letra “e”, pode executar
ZSCAN mysortedset 0 MATCH *e*#