Українська
Українська English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 







Використання команд сканування в Redis на Linux
Redis, сховище структур даних у пам’яті з відкритим вихідним кодом, відоме своєю швидкістю та універсальністю як база даних типу “ключ-значення”. Однією з його потужних функцій є можливість інкрементального ітераційного перегляду наборів даних за допомогою команд сканування. Це особливо корисно при роботі з великими наборами даних, оскільки дозволяє ефективно шукати дані, не перевантажуючи сервер. Для користувачів на виділеному сервері Linux використання команд сканування в Redis може підвищити продуктивність роботи з даними за рахунок точної, оптимізованої для ресурсів обробки наборів даних. У цій статті ми розглянемо, як ефективно використовувати команди сканування в Redis в середовищі Linux, пропонуючи детальні приклади і кращі практики для управління і пошуку даних в масштабі..
Що таке команди сканування?
Команди сканування у Redis надають спосіб ітерації над ключами, наборами, хешами та відсортованими наборами у неблокуючий спосіб. На відміну від команди KEYS, яка може бути небезпечною для великих наборів даних, оскільки повертає всі відповідні ключі одразу, команди сканування повертають невелику кількість елементів за раз. Це мінімізує вплив на продуктивність і дозволяє виконувати інкрементні ітерації
Команди сканування ключів
- SCAN: Перебирає ключі у просторі ключів.
- SSCAN: Перебирає елементи у наборі.
- HSCAN: Перебір полів і значень у хеші.
- ZSCAN: Перебирає члени та оцінки у відсортованому наборі.
Базовий синтаксис команд сканування
Кожна команда сканування має схожий синтаксис
- курсор: Ціле число, яке представляє позицію, з якої слід почати сканування. Щоб почати нове сканування, використовуйте 0.
- Шаблон збігу: (необов’язково) Шаблон для фільтрації повернених ключів. Підтримує шаблони у стилі glob.
- COUNT кількість: (необов’язково) Підказка Redis про те, скільки елементів повертати в кожній ітерації.
Встановлення Redis у Linux
Для CentOS/RHEL використовуйте
Після встановлення запустіть сервер Redis
Підключення до Redis
Відкрийте термінал і підключіться до вашого екземпляра Redis за допомогою Redis CLI
Тепер ви можете виконувати команди Redis в CLI
Використання команди SCAN
Приклад 1: Базове сканування
Щоб отримати всі ключі в базі даних Redis, ви можете використовувати
SCAN 0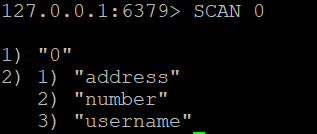
Ця команда поверне курсор і список ключів
Приклад 2: Використання MATCH для фільтрації ключів
Якщо ви хочете знайти ключі, які відповідають певному шаблону, наприклад, ключі, що починаються з “user:”, ви можете використати
Ця команда повертає тільки ключі, які починаються з “user:”
Приклад 3: Вказівка COUNT
Щоб підказати, скільки ключів Redis має повертати в кожній ітерації, ви можете вказати лічильник
Це буде спроба повернути приблизно 10 ключів. Зауважте, що фактична кількість повернених ключів може бути меншою
Приклад 4: Перебір усіх ключів
Щоб перебрати всі ключі за кілька ітерацій, вам потрібно відстежувати курсор, який повертається. Ось простий приклад сценарію командного рядка:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Process the result as needed
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Update the cursor
if [[ "$cursor" == "0" ]]; then
break # Stop when the cursor is back to 0
fi
doneВикористання команди SSCAN
Команда SSCAN використовується для ітераційного перебору елементів у множині. Її синтаксис подібний до синтаксису команди SCAN
Приклад використання SSCAN
Крок 1: Створення множини та додавання елементів
Створимо множину з назвою myset і додамо до неї деякі елементи
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"Крок 2: Використання команди SSCAN
Тепер, коли у нас є множина myset, ми можемо використовувати команду SSCAN для ітераційного перегляду її елементів
- Базова команда SSCAN:Припустимо, у вас є множина з назвою “myset”. Щоб переглянути її елементи
SSCAN myset 0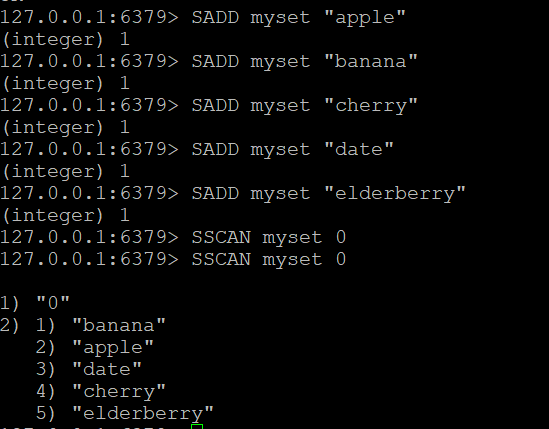
- За допомогою MATCH:Щоб відфільтрувати елементи набору на основі шаблону і додати деякі елементи, що містять слово “манго” та інші варіації:
SSCAN myset 0 MATCH mango:*
- Ітерація по множині:Ви можете використовувати цикл для ітерації по множині :
#!/bin/bash
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor)
# Print the elements returned by SSCAN
echo "$result"
# Update the cursor for the next iteration
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Break the loop if cursor is back to 0
if [[ "$cursor" == "0" ]]; then
break
fi
doneЗапуск скрипта
- Збережіть скрипт як scan_myset.sh.
- Зробіть його виконуваним
- Запустіть скрипт
./scan_myset.sh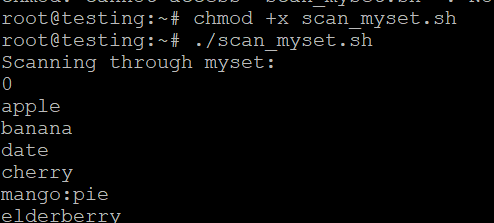
Використання команд HSCAN та ZSCAN
Команда HSCAN
Команда HSCAN виконує ітераційний перебір полів та значень у хеші
Команда HSCAN використовується для перебору полів і значень у хеші
Крок 1: Створення хешу і додавання полів
- Створіть хеш з ім’ям myhash і додайте до нього кілька полів:
Крок 2: Використання HSCAN для перебору хешу
- Використовуйте команду HSCAN для перебору полів в myhash:
HSCAN myhash 0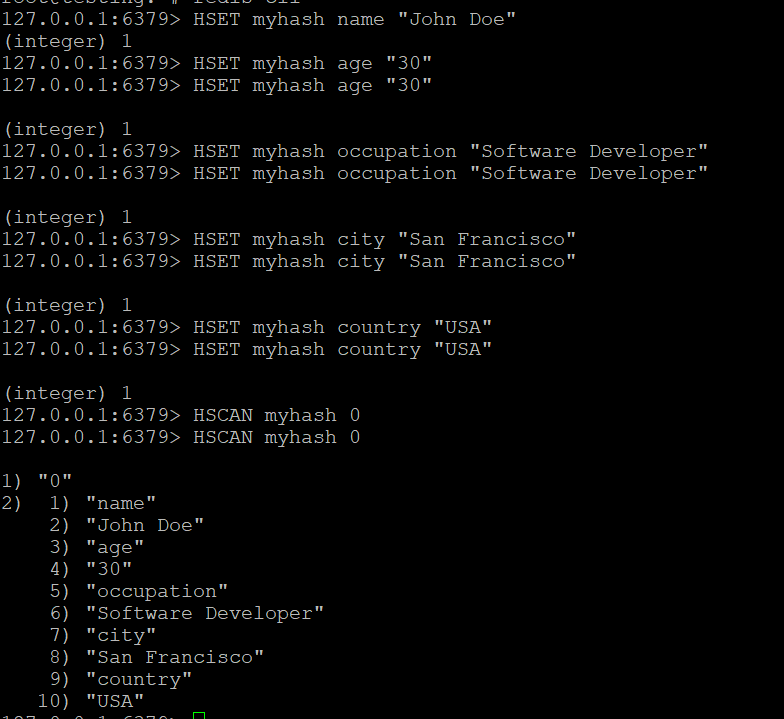
Команда ZSCAN
ZSCAN – це команда Redis, яка використовується для інкрементного перебору елементів відсортованої множини. Вона дозволяє отримувати елементи разом з їхніми оцінками у ефективний і неблокуючий спосіб. Ця команда особливо корисна для роботи з великими відсортованими множинами, де отримання всіх елементів за один раз може бути непрактичним. Команда ZSCAN виконує ітераційний перебір елементів і оцінок у відсортованій множині
Крок 1: Створення відсортованої множини та додавання елементів
Створимо відсортовану множину з назвою mysortedset і додамо деякі елементи з оцінками
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"Базова команда ZSCAN:Щоб почати сканування відсортованої множини, використовуйте
ZSCAN mysortedset 0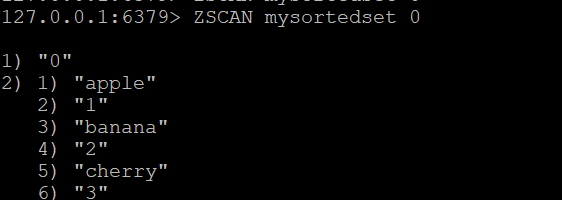
Крок 2: Використання MATCH для фільтрації членів (необов’язково)
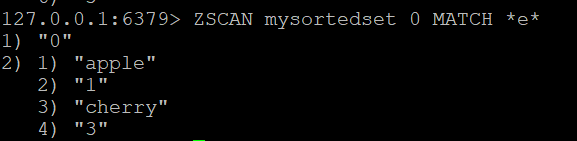
Якщо ви хочете відфільтрувати організації, повернуті ZSCAN, ви можете скористатися опцією MATCH. Наприклад, щоб знайти учасників, які містять літеру “e”, ви можете виконати
ZSCAN mysortedset 0 MATCH *e*