Français
Français English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 





Utilisation des commandes de balayage dans Redis sous Linux
Redis, un magasin de structures de données en mémoire open-source, est connu pour sa rapidité et sa polyvalence en tant que base de données clé-valeur. L’une de ses puissantes fonctionnalités est la possibilité d’itérer de manière incrémentale dans les ensembles de données à l’aide de commandes de balayage. Cette fonction est particulièrement utile lorsqu’il s’agit de grands ensembles de données, car elle permet d’extraire efficacement les données sans surcharger le serveur. Pour les utilisateurs d’un serveur Linux dédié, l’utilisation de commandes de balayage dans Redis peut améliorer les performances de traitement des données en permettant un traitement précis et optimisé des ensembles de données. Dans cet article, nous allons voir comment utiliser efficacement les commandes de balayage dans Redis au sein d’un environnement Linux, en proposant des exemples détaillés et les meilleures pratiques pour gérer et récupérer des données à grande échelle
Que sont les commandes de balayage ?
Les commandes de balayage de Redis permettent d’itérer sur des clés, des ensembles, des hachages et des ensembles triés de manière non bloquante. Contrairement à la commande KEYS, qui peut être dangereuse pour les grands ensembles de données car elle renvoie toutes les clés correspondantes en même temps, les commandes de balayage renvoient un petit nombre d’éléments à la fois. Cela minimise l’impact sur les performances et permet une itération incrémentale
Commandes de balayage des clés
- SCAN: parcourt les clés de l’espace-clé.
- SSCAN: parcourt les éléments d’un ensemble.
- HSCAN: parcourt les champs et les valeurs d’un hachage.
- ZSCAN: parcourt les membres et les notes d’un ensemble trié.
Syntaxe de base des commandes d’analyse
Chaque commande d’analyse a une syntaxe similaire
- curseur: Un nombre entier qui représente la position à partir de laquelle le balayage doit commencer. Pour commencer un nouveau balayage, utilisez 0.
- MATCH pattern: (optionnel) Un motif pour filtrer les clés renvoyées. Prend en charge les motifs de type “glob”.
- COUNT count: (facultatif) Indication à Redis du nombre d’éléments à renvoyer à chaque itération.
Installation de Redis sous Linux
Pour CentOS/RHEL, utilisez
Une fois installé, démarrez le serveur Redis
Connexion à Redis
Ouvrez votre terminal et connectez-vous à votre instance Redis en utilisant le CLI Redis
Vous pouvez maintenant exécuter des commandes Redis dans le CLI
Utilisation de la commande SCAN
Exemple 1 : SCAN de base
Pour récupérer toutes les clés de la base de données Redis, vous pouvez utiliser
SCAN 0#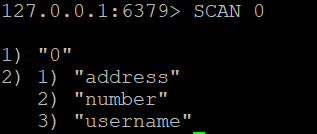
Cette commande renvoie un curseur et une liste de clés
Exemple 2 : Utilisation de MATCH pour filtrer les clés
Si vous souhaitez trouver les clés qui correspondent à un modèle spécifique, par exemple les clés qui commencent par “user :”, vous pouvez utiliser la commande MATCH
Cette commande ne renvoie que les clés qui commencent par “user :”
Exemple 3 : Spécifier COUNT
Pour indiquer le nombre de clés que Redis doit renvoyer à chaque itération, vous pouvez spécifier un compte
Cette méthode tentera de renvoyer environ 10 clés. Notez que le nombre réel de clés retournées peut être inférieur à ce chiffre
Exemple 4 : Itération sur toutes les clés
Pour parcourir toutes les clés en plusieurs itérations, vous devez garder une trace du curseur renvoyé. Voici un exemple simple de script shell : cursor=0#
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Process the result as needed
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Update the cursor
if [[ "$cursor" == "0" ]]; then
break # Stop when the cursor is back to 0
fi
done
Utilisation de la commande SSCAN
La commande SSCAN est utilisée pour parcourir les éléments d’un ensemble. Sa syntaxe est similaire à celle de SCAN
Exemple de SSCAN
Étape 1 : Créer un ensemble et ajouter des éléments
Créons un ensemble appelé myset et ajoutons-y des éléments
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"##Étape 2 : Utiliser la commande SSCAN
Maintenant que nous disposons d’un ensemble nommé myset, nous pouvons utiliser la commande SSCAN pour parcourir ses éléments
- Commande SSCAN de base: Supposons que vous disposiez d’un ensemble appelé “myset”. Pour parcourir ses éléments
SSCAN myset 0##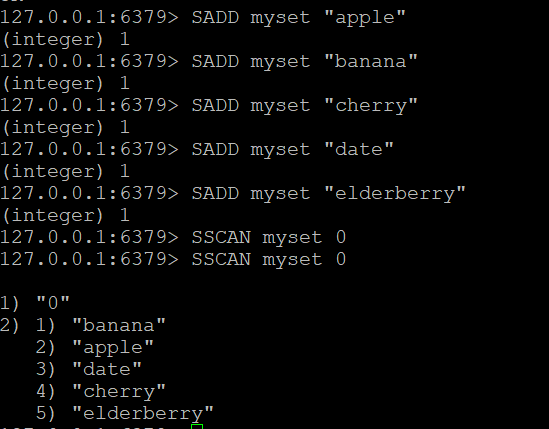
- Utilisation de MATCH:Pour filtrer les éléments d’un ensemble sur la base d’un modèle et ajouter des éléments comprenant le mot “mango” et d’autres variations:
SSCAN myset 0 MATCH mango:*#####
- Itérer à travers un ensemble:Vous pouvez utiliser une boucle pour itérer à travers un ensemble :
#!/bin/bash#####
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor)
# Print the elements returned by SSCAN
echo "$result"
# Update the cursor for the next iteration
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Break the loop if cursor is back to 0
if [[ "$cursor" == "0" ]]; then
break
fi
done
Exécution du script
- Enregistrez le script sous le nom de scan_myset.sh.
- Rendez-le exécutable
- Exécutez le script
./scan_myset.sh##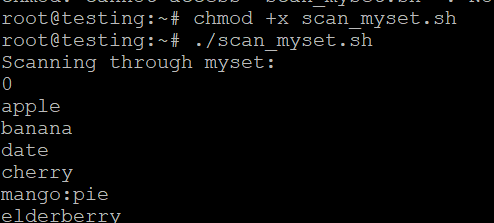
Utilisation des commandes HSCAN et ZSCAN
Commande HSCAN
La commande HSCAN parcourt les champs et les valeurs d’un hachage
La commande HSCAN est utilisée pour parcourir les champs et les valeurs d’un hachage
Étape 1 : Création d’un hachage et ajout de champs
- Créez un hachage nommé myhash et ajoutez-y des champs :
Étape 2 : Utiliser HSCAN pour parcourir le hachage
- Utilisez la commande HSCAN pour parcourir les champs de myhash :
HSCAN myhash 0##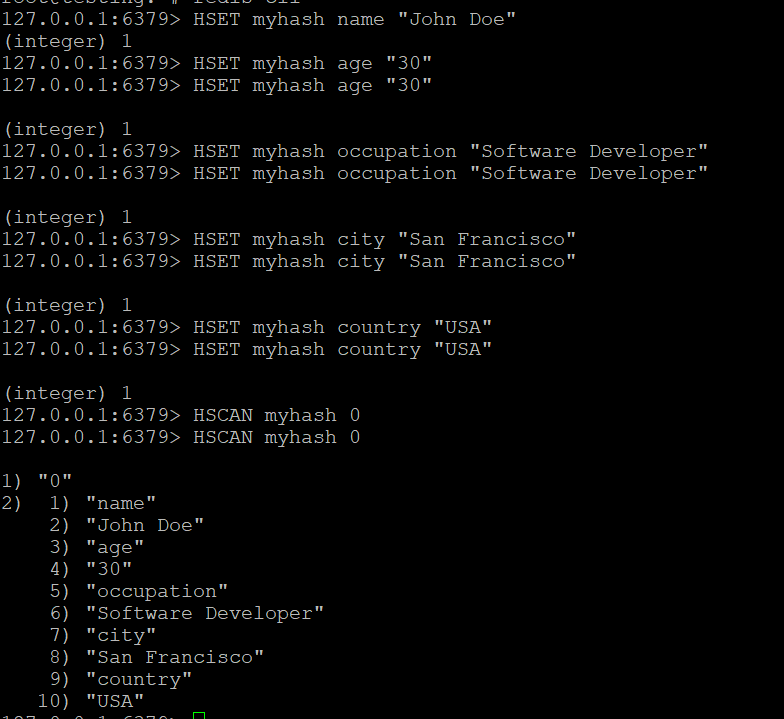
Commande ZSCAN
ZSCAN est une commande Redis utilisée pour parcourir les membres d’un ensemble trié de manière incrémentielle. Elle vous permet de récupérer les membres avec leurs scores associés d’une manière efficace et non bloquante. Cette commande est particulièrement utile pour travailler avec de grands ensembles triés où la récupération de tous les membres en une seule fois peut ne pas être pratique. La commande ZSCAN itère à travers les membres et les scores dans un ensemble trié
Étape 1 : Créer un ensemble trié et ajouter des membres
Créons un ensemble trié appelé mysortedset et ajoutons quelques membres avec des scores
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"#Commande ZSCAN de base :Pour commencer à analyser l’ensemble trié, utilisez
ZSCAN mysortedset 0##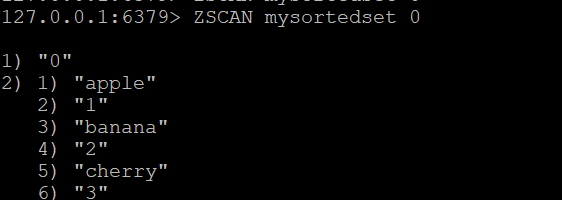
Étape 2 : Utilisation de MATCH pour filtrer les membres (facultatif)
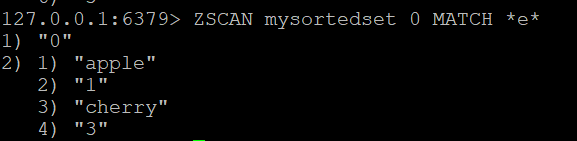
Si vous souhaitez filtrer les membres renvoyés par ZSCAN, vous pouvez utiliser l’option MATCH. Par exemple, pour trouver les membres qui contiennent la lettre “e”, vous pouvez exécuter l’option MATCH
ZSCAN mysortedset 0 MATCH *e*##