中文 (中国)
中文 (中国) English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia 







在Linux上使用Redis的扫描命令
Redis,一个开源的内存数据结构存储,以其速度和作为键值数据库的多功能性而闻名。它的一个强大特性是能够使用扫描命令逐步遍历数据集。这在处理大数据集时特别有用,因为它允许高效的数据检索而不会使服务器过载。对于在专用Linux服务器上的用户,使用scan命令可以通过允许精确、资源优化的数据集处理来增强数据处理性能。在本文中,我们将探讨如何在Linux环境中有效使用scan命令,提供详细示例和最佳实践,以便在大规模管理和检索数据时使用。
什么是扫描命令?
Redis中的scan命令提供了一种非阻塞方式来遍历键、集合、哈希和有序集合。与可能对大数据集危险的KEYS命令不同,后者一次返回所有匹配的键,scan命令一次返回少量元素。这最小化了性能影响,并允许增量迭代。
主要扫描命令
- SCAN:遍历键空间中的键。
- SSCAN:遍历集合中的元素。
- HSCAN:遍历哈希中的字段和值。
- ZSCAN:遍历有序集合中的成员和分数。
扫描命令的基本语法
每个扫描命令具有类似的语法:
- cursor:一个整数,表示开始扫描的位置。要开始新的scan,使用0。
- MATCH pattern:(可选)用于过滤返回的键的模式。支持通配符样式的模式。
- COUNT count:(可选)给Redis的提示,关于每次迭代中要返回多少元素。
在Linux上安装Redis
对于CentOS/RHEL,使用:
安装完成后,启动Redis服务器:
连接到Redis
打开您的终端并使用Redis CLI连接到您的Redis实例:
您现在可以在CLI中执行Redis命令。
使用SCAN命令
示例1:基本SCAN
要检索Redis数据库中的所有键,可以使用:
SCAN 0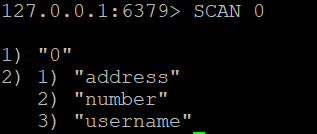
此命令将返回一个游标和一个键的列表。
示例2:使用MATCH过滤键
如果您想查找匹配特定模式的键,例如以”user:”开头的键,可以使用:
此命令仅返回以”user:”开头的键。
示例3:指定COUNT
要提示Redis在每次迭代中应返回多少键,可以指定一个计数:
这将尝试返回大约10个键。请注意,实际返回的数量可能少于此。
示例4:遍历所有键
要在多个迭代中遍历所有键,您需要跟踪返回的游标。以下是一个简单的shell脚本示例:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Process the result as needed
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Update the cursor
if [[ "$cursor" == "0" ]]; then
break # Stop when the cursor is back to 0
fi
done使用SSCAN命令
SSCAN命令用于遍历集合中的元素。其语法与SCAN类似:
SSCAN示例
步骤1:创建一个集合并添加元素
让我们创建一个名为myset的集合并添加一些元素:
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"步骤2:使用SSCAN命令
现在我们有一个名为myset的集合,我们可以使用SSCAN命令遍历其元素。
- 基本SSCAN命令:假设您有一个名为”myset”的集合。要扫描其元素:
SSCAN myset 0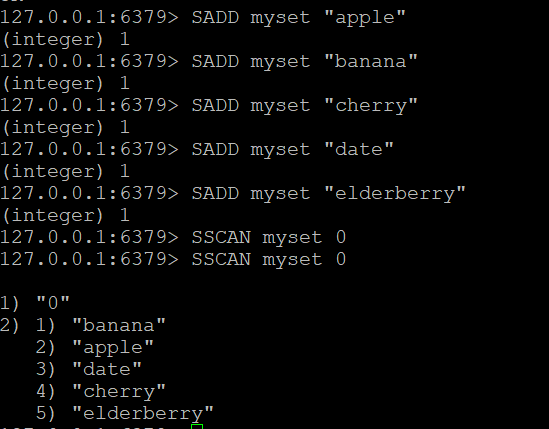
- 使用MATCH:根据模式过滤集合中的元素,并添加一些包含”mango”及其他变体的元素:
SSCAN myset 0 MATCH mango:*
- 遍历集合:您可以使用循环遍历集合:
#!/bin/bash
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor)
# Print the elements returned by SSCAN
echo "$result"
# Update the cursor for the next iteration
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Break the loop if cursor is back to 0
if [[ "$cursor" == "0" ]]; then
break
fi
done运行脚本
- 将脚本保存为scan_myset.sh。
- 使其可执行:
- 运行脚本:
./scan_myset.sh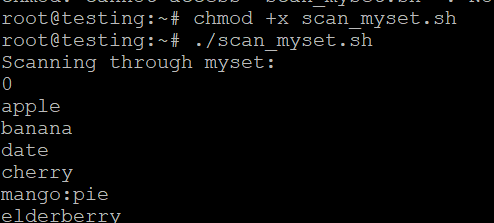
使用HSCAN和ZSCAN命令
HSCAN命令
HSCAN命令遍历哈希中的字段和值:
HSCAN命令用于遍历哈希中的字段和值。
步骤1:创建一个哈希并添加字段
- 创建一个名为myhash的哈希并添加一些字段:
步骤2:使用HSCAN遍历哈希
- 使用HSCAN命令遍历myhash中的字段:
HSCAN myhash 0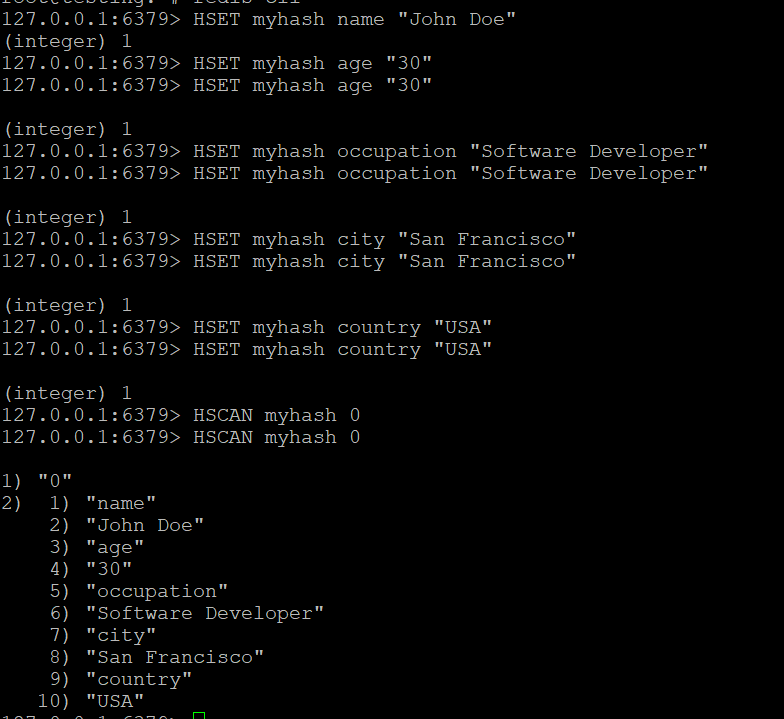
ZSCAN命令
ZSCAN是一个Redis命令,用于增量遍历有序集合的成员。它允许您以高效和非阻塞的方式检索成员及其相关分数。此命令在处理大型有序集合时特别有用,因为一次获取所有成员可能不切实际。
ZSCAN命令遍历有序集合中的成员和分数:
步骤1:创建一个有序集合并添加成员
让我们创建一个名为mysortedset的有序集合,并添加一些带分数的成员:
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"基本ZSCAN命令:
要开始扫描有序集合,请使用:
ZSCAN mysortedset 0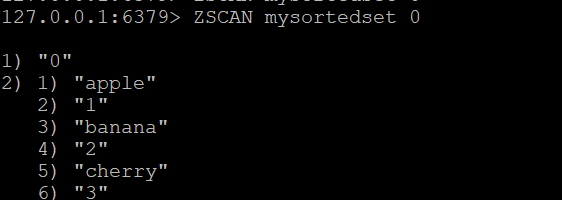
步骤2:使用MATCH过滤成员(可选)
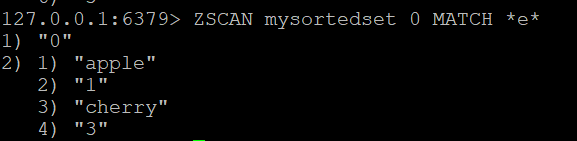
如果您想过滤ZSCAN返回的成员,可以使用MATCH选项。例如,要查找包含字母”e”的成员,可以运行:
ZSCAN mysortedset 0 MATCH *e*