 中文 (中国)
中文 (中国) English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia 





在 Linux 中检查 RAM 使用情况的命令和工具
在 Linux 中监控 RAM 使用情况,意味着查询内核的内存子系统以获取物理内存分配、swap 利用率以及每个进程驻留集大小的指标。最直接的方法是使用内置工具 — free、top、htop、ps、vmstat 和 smem — 每个工具都展示内存层次结构的不同层面,从系统级总量到每个进程的比例集大小(PSS)。
过度的内存压力会触发 Linux 内存不足(OOM)终止程序,它会强制终止进程以回收 RAM。了解哪些命令揭示哪些指标——以及这些指标的实际含义——是被动救火与主动容量管理之间的区别。本指南涵盖所有主要工具、它们读取的内核数据源,以及即使是经验丰富的管理员也会遇到的边缘情况。

为什么 RAM 监控在 Linux 服务器上至关重要
Linux 内存管理是刻意激进的。内核将所有可用 RAM 用作页面缓存以加速磁盘 I/O,这意味着报告接近零可用内存的系统不一定处于压力之下——它可能只是在高效地进行缓存。误读这种行为是解读原始内存数据时最常见的错误之一。
持续监控 RAM 的主要原因:
- 防止 OOM 终止程序:在内核终止关键服务之前识别内存消耗大的进程。
- 检测 swap 使用情况:大量 swap 活动(交换)表明 RAM 耗尽,并导致严重的 I/O 延迟。
- 诊断内存泄漏:RSS 随时间持续增长的进程表明存在应用程序级别的泄漏。
- 容量规划:趋势数据为垂直扩展或工作负载重新分配的决策提供依据。
- 性能调优:调整
vm.swappiness、大页面和 NUMA 拓扑需要基准内存数据。
在 VPS 托管环境中,资源由虚拟机监控程序限制共享或限制,准确的 RAM 监控尤为关键——达到内存上限会在任何警报触发之前悄无声息地降低性能。

了解 Linux 内存术语
在运行任何命令之前,您需要了解输出列的实际含义。
| 术语 | 定义 |
|---|---|
| Total | 已安装的物理 RAM(或分配给虚拟机的 RAM) |
| Used | 进程和内核结构主动消耗的内存 |
| Free | 完全未使用的 RAM——通常低得具有误导性 |
| Shared | 由 tmpfs 使用并在进程间共享的内存 |
| Buff/Cache | 内核缓冲区和页面缓存——可按需回收 |
| Available | 可用于新分配而无需交换的 RAM 的实际估计值 |
| Swap Used | 从 RAM 转移到 swap 分区或 swap 文件的数据 |
| VSZ(虚拟大小) | 进程保留的总虚拟地址空间 |
| RSS(驻留集大小) | 进程当前占用的物理 RAM |
| PSS(比例集大小) | 针对共享内存调整后的 RSS——最准确的每进程指标 |
| USS(唯一集大小) | 进程独占的内存;进程退出时完全释放 |
关键见解:在评估系统是否有足够 RAM 用于新工作负载时,始终使用 free -h 中的 Available 列,而不是 Free 列。Free 列忽略了可回收的缓存,会导致误报。
/proc/meminfo 文件:权威来源
本文描述的每个工具都从 /proc/meminfo 读取数据,这是内核实时维护的虚拟文件。直接检查它可以获得最详细的可用数据:
cat /proc/meminfo需要关注的关键字段:
MemTotal— 可用 RAM 总量MemFree— 完全空闲的 RAMMemAvailable— 新进程可用 RAM 的估计值Buffers— 原始磁盘块缓存Cached— 文件的页面缓存SwapTotal/SwapFree— swap 容量和可用性Dirty— 等待写入磁盘的内存(高值表示 I/O 压力)HugePages_Total/HugePages_Free— 大页面分配状态Slab— 内核数据结构缓存(在繁忙的 NFS 或数据库服务器上可能增长很大)
理解 /proc/meminfo 可以让您在完整上下文中解读其他所有工具的输出。

使用 free 命令检查 RAM
free 是获取系统级内存快照的最快方式。它直接从 /proc/meminfo 读取数据,并将输出格式化为人类可读的表格。
基本用法
free默认输出以千字节为单位。使用标志获取更易读的格式:
free -h # Human-readable (MB/GB)
free -m # Output in megabytes
free -g # Output in gigabytes
free -s 5 # Refresh every 5 seconds (continuous monitoring)
free -h --si # Use SI units (1000-based) instead of binary (1024-based)示例输出解析
total used free shared buff/cache available
Mem: 15Gi 4.2Gi 1.1Gi 312Mi 9.8Gi 10.9Gi
Swap: 2.0Gi 128Mi 1.9Gi在此示例中,系统看起来只有 1.1 GB 可用,但实际上 10.9 GB 可供新进程使用,因为内核会按需回收 buff/cache。这是理解 free 输出最重要的一点。
边缘情况:swap 使用作为警告信号
即使生产服务器上有少量 swap 使用(Swap: used > 0)也值得调查。这意味着内核已经决定某些内存页面最好存储在磁盘上而不是 RAM 中——这是工作集超过物理内存的迹象。
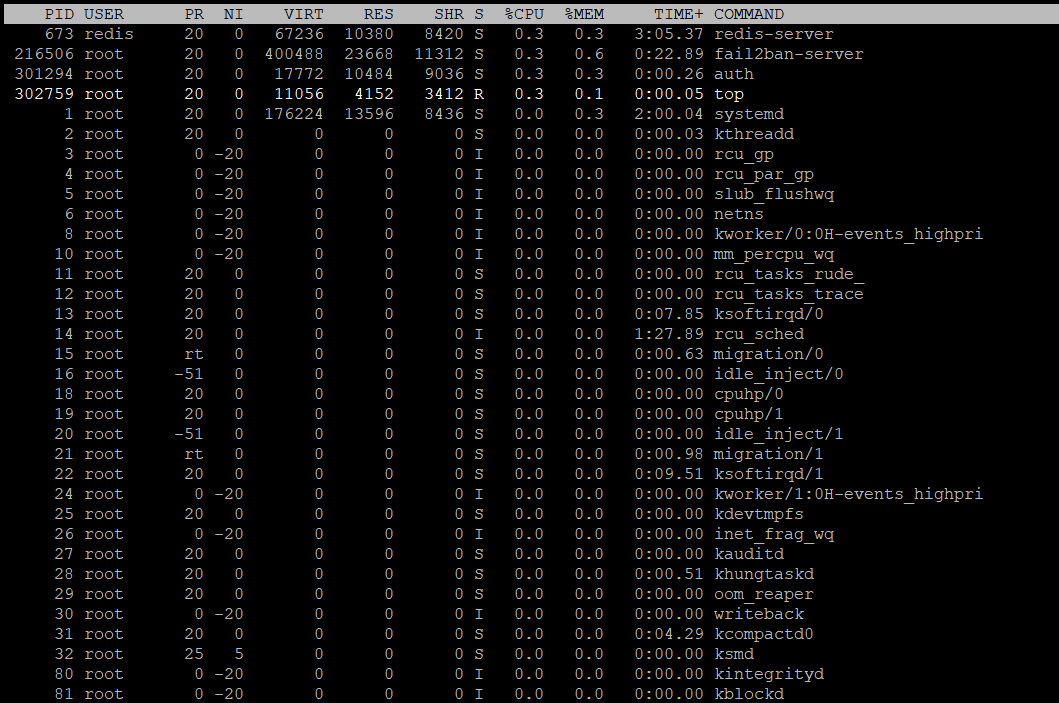
使用 top 命令检查 RAM
top 提供系统资源使用情况的持续更新实时视图,将 CPU 和内存统计数据与排名进程列表相结合。
toptop 中的关键内存字段
在 top 界面顶部,两行显示内存统计数据:
MiB Mem : 16384.0 total, 1126.4 free, 4301.2 used, 10956.4 buff/cache
MiB Swap: 2048.0 total, 1920.0 free, 128.0 used. 11200.0 avail Mem在进程表中,最相关的内存列是:
- VIRT — 虚拟内存大小(相当于 VSZ)
- RES — 驻留物理内存(RSS)
- SHR — RES 的共享内存部分
- %MEM — 使用的总物理 RAM 百分比
实用的 top 交互命令
| 按键 | 操作 |
|---|---|
M | 按内存使用率(%MEM)排序进程 |
P | 按 CPU 使用率排序 |
k | 通过 PID 终止进程 |
1 | 切换每个 CPU 核心统计数据 |
f | 添加/删除显示字段 |
W | 保存当前配置 |
以非交互方式运行 top
对于脚本编写和日志捕获,以批处理模式运行 top:
top -b -n 1 | head -30这会输出单个快照——对基于 cron 的监控脚本很有用。
使用 htop 检查 RAM
htop 是一个增强的基于 ncurses 的进程查看器,呈现与 top 相同的底层数据,但界面更加易用。它在大多数发行版上默认未安装。
安装
# Debian / Ubuntu
apt-get install htop
# RHEL / CentOS / AlmaLinux / Rocky Linux
yum install htop
# or on newer versions:
dnf install htop
# Alpine Linux
apk add htophtop 相比 top 的优势
- 彩色编码的内存条,一目了然地区分已用内存、缓冲区和缓存
- 水平和垂直进程树视图(
F5) - 支持鼠标点击和滚动
- 多选以进行批量进程管理
- 内置搜索(
F3)和过滤(F4),无需记忆按键绑定 - 在标题中突出显示可用内存
htop 内存条颜色图例
| 颜色 | 含义 |
|---|---|
| 绿色 | 已用内存(进程) |
| 蓝色 | 缓冲区缓存 |
| 黄色/橙色 | 页面缓存 |
| 红色 | 已用 swap |
专业提示:在 htop 中,按 F2(设置)> 显示选项 > 启用”显示 CPU 频率”和”详细 CPU 时间”,以获得与内存数据并排的更完整视图。
使用 ps 命令检查 RAM
ps(进程状态)查询内核的进程表,可以排序和过滤以识别某一时间点的最大内存消耗者。
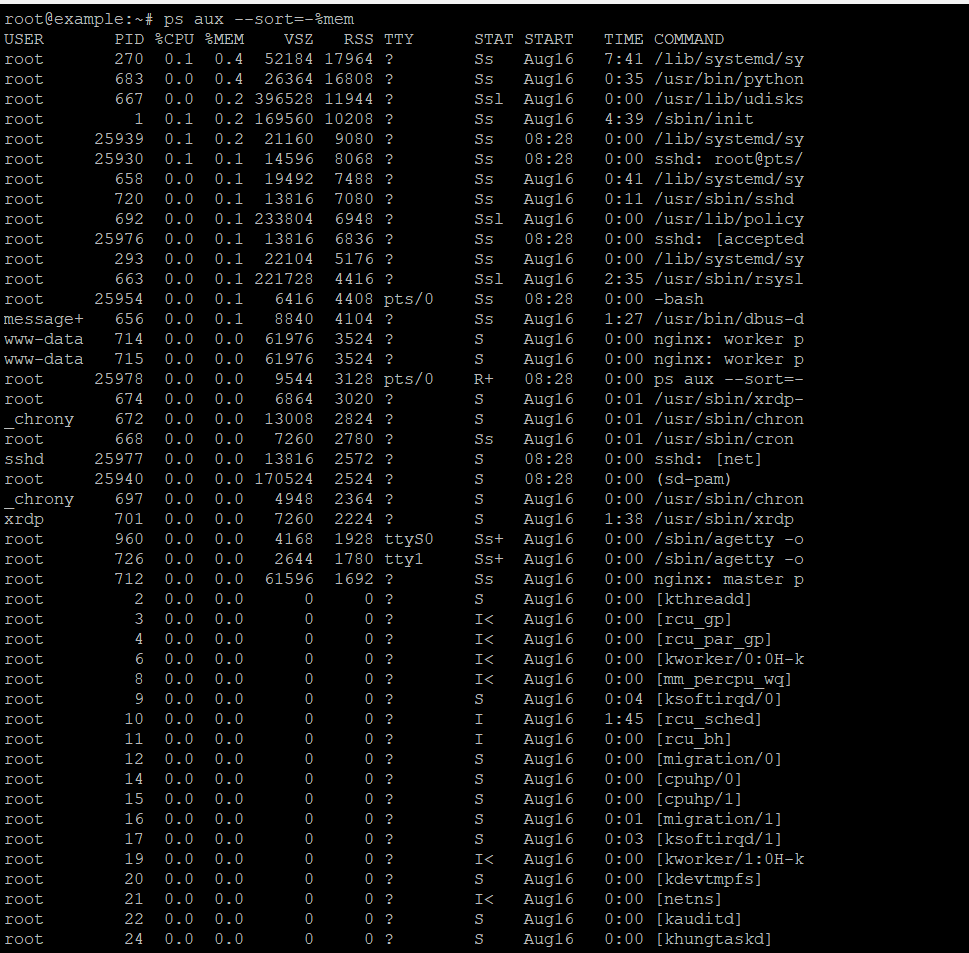
按内存消耗排序进程
ps aux --sort=-%mem输出列解析
| 列 | 描述 |
|---|---|
USER | 进程的所有者 |
PID | 进程 ID |
%CPU | 自进程启动以来的 CPU 利用率 |
%MEM | 使用的物理 RAM 百分比(RSS / MemTotal) |
VSZ | 虚拟内存大小(KB) |
RSS | 驻留集大小(KB) |
TTY | 控制终端 |
STAT | 进程状态(S=休眠,R=运行,Z=僵尸,D=不可中断等待) |
START | 进程启动时间 |
TIME | 累计消耗的 CPU 时间 |
COMMAND | 命令名称和参数 |
实用单行命令
显示前 10 个内存消耗进程,输出人类可读格式:
ps aux --sort=-%mem | head -11显示特定进程名称的内存使用情况(例如 Apache):
ps aux | grep apache2 | awk '{sum += $6} END {print sum/1024 " MB"}'这会汇总所有 apache2 工作进程的 RSS 值——对于了解多进程 Web 服务器的真实占用至关重要。
重要注意事项:ps 显示 RSS,会重复计算共享库。如果 20 个 Apache 工作进程各自映射同一个 50 MB 共享库,ps 会报告它们之间有 1,000 MB 的共享库使用量,而实际物理成本只有 50 MB。使用 smem 进行准确核算。
使用 smem 检查 RAM
smem 是 Linux 上最准确的每进程内存核算工具,因为它报告 PSS(比例集大小)——共享内存按比例分配给映射它的所有进程,消除了基于 RSS 工具固有的重复计算问题。
安装
# Ubuntu / Debian
apt-get install smem
# CentOS / RHEL 7
yum install smem
# RHEL 8+ / AlmaLinux / Rocky Linux
dnf install smem
# Alternatively, install via pip
pip install smem基本用法
smem实用的 smem 选项
smem -r # Sort by RSS (descending)
smem -s pss -r # Sort by PSS (most accurate, descending)
smem -u # Aggregate by user
smem -m # Show system-wide memory map
smem -p # Show percentages instead of raw KB
smem -k # Show values in KB
smem -t # Show totals row
smem --pie name # Generate a pie chart (requires matplotlib)
smem -P apache2 # Filter by process name patternPSS 与 RSS:为什么重要
考虑一个运行 10 个 Node.js 工作进程的服务器,每个进程共享一个 100 MB 的 V8 运行时库:
- 每个进程的 RSS:200 MB(100 MB 共享 + 100 MB 私有)
- 报告的总 RSS:2,000 MB
- 每个进程的 PSS:110 MB(100 MB 的 1/10 份额 + 100 MB 私有)
- 报告的总 PSS:1,100 MB
- 实际使用的物理 RAM:1,100 MB
在此场景中,RSS 高估了近 2 倍的使用量。在独立服务器上做出扩展决策时,使用 smem 的 PSS 可以给您提供真实数据。
使用 vmstat 检查 RAM
vmstat(虚拟内存统计)提供内存、swap、I/O 和 CPU 活动的更广泛视图,非常适合诊断系统级内存压力,而不是单个进程问题。
vmstat 2 10 # Report every 2 seconds, 10 times关键内存列
| 列 | 描述 |
|---|---|
swpd | 已用虚拟内存(swap) |
free | 空闲内存 |
buff | 用作缓冲区的内存 |
cache | 用作缓存的内存 |
si | 从磁盘换入的内存(KB/s) |
so | 换出到磁盘的内存(KB/s) |
关键信号:在运行的 vmstat 流中,非零的 si(换入)和 so(换出)值表示正在进行活跃的交换——这是内存耗尽的明确信号。即使 so 偶尔出现峰值,也可能导致应用程序延迟峰值达数百毫秒。
使用 sar 检查 RAM(系统活动报告器)
来自 sysstat 软件包的 sar 记录历史内存数据,支持回溯分析——这是实时工具无法提供的功能。
安装
apt-get install sysstat # Debian/Ubuntu
yum install sysstat # CentOS/RHEL用法
sar -r 1 5 # Memory stats every 1 second, 5 times
sar -r -f /var/log/sysstat/sa$(date +%d) # Today's historical data
sar -S 1 5 # Swap statisticssar 对于回答诸如”凌晨 3 点是否有内存峰值导致应用程序崩溃?”这类问题非常有价值——这是任何实时工具在事后都无法回答的问题。
使用 /proc/<PID>/status 和 /proc/<PID>/smaps 检查 RAM
对于深度的每进程分析,内核直接在 /proc 中公开详细的内存映射。
快速每进程内存检查
cat /proc/$(pgrep nginx | head -1)/status | grep -E "VmRSS|VmPeak|VmSize|VmSwap"输出示例:
VmPeak: 512340 kB
VmSize: 498120 kB
VmRSS: 102400 kB
VmSwap: 0 kBVmPeak— 此进程曾达到的峰值虚拟内存大小VmRSS— 当前驻留集大小VmSwap— 此进程已换出的内存量
使用 smaps 查看详细内存映射
cat /proc/$(pgrep mysql | head -1)/smaps | grep -E "^(Size|Rss|Pss|Shared|Private)"这揭示了每个内存映射(堆、栈、共享库、匿名映射)及其各自的 RSS 和 PSS 值——这是无需分析器即可获得的最详细内存视图。
工具比较:选择正确的命令
| 工具 | 范围 | 指标类型 | 实时 | 历史 | 共享内存准确性 | 最佳使用场景 |
|---|---|---|---|---|---|---|
free | 系统级 | 总量/可用量 | 是 | 否 | 不适用 | 快速健康检查 |
top | 每进程 + 系统 | RSS, %MEM | 是 | 否 | 低(RSS) | 交互式监控 |
htop | 每进程 + 系统 | RSS, %MEM | 是 | 否 | 低(RSS) | 交互式监控(首选) |
ps | 每进程 | RSS, VSZ | 快照 | 否 | 低(RSS) | 脚本编写、排序 |
smem | 每进程 | PSS, USS, RSS | 快照 | 否 | 高(PSS) | 准确内存核算 |
vmstat | 系统级 | Swap I/O,空闲 | 是 | 否 | 不适用 | 诊断 swap 压力 |
sar | 系统级 | 所有指标 | 否 | 是 | 不适用 | 事后分析 |
/proc/meminfo | 系统级 | 原始内核数据 | 是 | 否 | 不适用 | 脚本编写、自动化 |
/proc/PID/smaps | 每进程 | 完整映射 | 是 | 否 | 高 | 深度进程分析 |
实用监控工作流程
工作流程 1:快速分类(60 秒内)
free -h # Step 1: Is Available memory critically low?
vmstat 1 5 # Step 2: Is active swapping occurring?
ps aux --sort=-%mem | head -15 # Step 3: Which processes are the top consumers?工作流程 2:识别内存泄漏
# Watch a specific process's RSS grow over time
watch -n 5 'ps -o pid,rss,vsz,comm -p $(pgrep your_app)'
# Or use smem with repeated snapshots
while true; do smem -P your_app -t; sleep 30; done工作流程 3:事后历史分析
sar -r -f /var/log/sysstat/sa$(date +%d --date='yesterday')工作流程 4:自动化告警脚本
#!/bin/bash
THRESHOLD=90
USED_PCT=$(free | awk '/^Mem:/ {printf "%.0f", $3/$2 * 100}')
if [ "$USED_PCT" -gt "$THRESHOLD" ]; then
echo "ALERT: RAM usage at ${USED_PCT}% on $(hostname)" | mail -s "Memory Alert" admin@example.com
fi此脚本可以放入 cron 作业中进行持续自动化监控——这在任何生产环境的带 cPanel 的 VPS 或裸机服务器上都是实际需要。
进阶:内核内存调优参数
一旦识别出内存压力,这些 sysctl 参数会直接影响行为:
# View current swappiness (default: 60)
sysctl vm.swappiness
# Reduce swap tendency (recommended for databases: 10)
sysctl -w vm.swappiness=10
# Increase dirty page write-back aggressiveness
sysctl -w vm.dirty_ratio=15
sysctl -w vm.dirty_background_ratio=5
# Drop page cache manually (use with caution on production)
sync; echo 3 > /proc/sys/vm/drop_cachesvm.swappiness 解释:值为 60 意味着当 RAM 使用率达到 40% 时内核将开始交换。对于数据库服务器(MySQL、PostgreSQL、Redis),将其设置为 10 可以将数据在 RAM 中保留更长时间,从而显著降低 I/O 延迟。对于桌面系统或 RAM 有限的系统,默认值更为合适。
常见陷阱和误解
陷阱 1:对低”free”内存感到恐慌
如前所述,Linux 有意将空闲 RAM 用作缓存。一个 free 只有 200 MB 但 available 有 8 GB 的系统是健康的。始终读取 Available 列。
陷阱 2:通过汇总 RSS 来估计总内存使用量
汇总所有进程的 ps RSS 值通常会超过总物理 RAM,这是由于共享库的重复计算。使用 smem -t 获取准确的系统总量。
陷阱 3:忽略 Slab 缓存
在繁忙的 NFS 客户端或拥有大量小文件的服务器上,内核 Slab 分配器可能消耗数 GB 的 RAM。检查 cat /proc/meminfo | grep Slab——这部分内存在技术上是可回收的,但不会出现在进程级工具中。
陷阱 4:将 VSZ 与实际内存使用量混淆
Java 应用程序可能显示 4 GB VSZ,但 RSS 只有 512 MB。VSZ 包括内存映射文件、已保留但未分配的堆以及共享库——其中大部分实际上从未加载到物理 RAM 中。
陷阱 5:忽视容器化工作负载的内存
在 Docker 容器内部,free 显示的是主机的总内存,而不是容器的 cgroup 限制。使用 cat /sys/fs/cgroup/memory/memory.usage_in_bytes 和 cat /sys/fs/cgroup/memory/memory.limit_in_bytes 获取准确的容器级指标。
设置持久 RAM 监控
对于生产环境,时间点命令是不够的。考虑以下方法实现持续可见性:
sysstat与 cron:自动启用sar历史数据收集。- Prometheus + Node Exporter:抓取
/proc/meminfo指标并将其公开给 Grafana 仪表板。 - Netdata:零配置实时监控,具有每秒粒度和内置内存异常检测。
- Zabbix 或 Nagios:企业级告警,具有可配置的内存阈值和升级策略。
在 GPU 托管基础设施上运行工作负载时,还需要监控 GPU VRAM 以及系统 RAM——nvidia-smi --query-gpu=memory.used,memory.free --format=csv 提供 GPU 内存的等效指标。
对于通过 VPS 控制面板管理的 Web 托管环境,大多数控制面板包含内置内存图表——但这些通常以 1-5 分钟的间隔轮询,会错过 vmstat 或 sar 能够捕获的短时间峰值。
技术决策矩阵:何时使用哪种工具
| 场景 | 推荐工具 | 命令 | |
|---|---|---|---|
| 快速系统健康检查 | free | free -h | |
| 立即找出最大内存消耗者 | ps 或 htop | `ps aux –sort=-%mem | head -15` |
| 准确的每进程核算 | smem | smem -s pss -r | |
| 诊断活跃的交换 | vmstat | vmstat 1 10 | |
| 调查过去的内存事件 | sar | sar -r -f /var/log/sysstat/saDD | |
| 深度分析特定进程 | /proc/PID/smaps | cat /proc/PID/smaps | |
| 持续生产监控 | Prometheus + Node Exporter | — | |
| 容器内存限制 | cgroup 文件系统 | cat /sys/fs/cgroup/memory/memory.usage_in_bytes |
关键要点清单
- 始终检查
free -h中的可用内存,而不是 Free 列,以评估实际余量。 - 在升级调查之前,使用
vmstat 1 5确认或排除活跃的交换。 - 当需要准确的每进程内存数据时,使用
smem -s pss -r而不是ps aux --sort=-%mem——尤其是在有许多进程共享库的服务器上。 - 在每台生产服务器配置完成后立即安装
sysstat,以启用历史sar数据收集。 - 在数据库服务器的
/etc/sysctl.conf中持久设置vm.swappiness=10,以最小化 swap 使用。 - 当标准工具无法解释观察到的内存压力时,检查
/proc/meminfo中的Slab和Dirty值。 - 对于容器化工作负载,读取 cgroup 内存文件——而不是
free——以获取准确的限制和使用情况。 - 在共享托管或 VPS 环境中,在正常运行期间建立内存基准,以便立即识别异常。
常见问题
Linux 中”free”和”available”内存有什么区别?
“Free”是完全没有当前用途的 RAM。”Available”是可以分配给新进程而不触发交换的内存的实际估计值——它包括可回收的页面缓存和缓冲区。在健康的 Linux 服务器上,”free”通常接近零,而”available”仍然很高。始终使用”available”进行容量评估。
为什么所有进程 RSS 值的总和会超过总物理 RAM?
RSS(驻留集大小)对每个映射共享内存(如共享库)的进程各计算一次。如果 50 个进程各自映射一个 100 MB 的共享库,总 RSS 总和会比实际物理成本多出 4,900 MB。使用带有 PSS 报告的 smem 来消除这种重复计算。
如何找出触发 Linux OOM 终止程序的进程?
运行 dmesg | grep -i "oom|killed process" 或 journalctl -k | grep -i oom。内核会在终止事件发生时记录确切的进程名称、PID 和内存统计数据,包括所有被评估进程的 oom_score。
高 swap 使用量意味着什么,严重程度如何?
持续的 swap 使用意味着系统的工作集超过了物理 RAM。内核通过将数据分页到磁盘来补偿,而磁盘通常比 RAM 访问慢 100-1,000 倍。即使适度的 swap 活动也会导致可测量的应用程序延迟。这是减少内存消耗、增加 RAM 或重新分配工作负载的明确信号。
我可以使用标准 Linux 命令监控 Docker 容器内的 RAM 使用情况吗?
容器内的标准命令(如 free)显示的是主机的总 RAM,而不是容器的 cgroup 限制。要获取准确的容器级指标,请读取 /sys/fs/cgroup/memory/memory.usage_in_bytes 获取当前使用量,读取 /sys/fs/cgroup/memory/memory.limit_in_bytes 获取配置的限制。或者,从主机使用 docker stats <container_name> 获取格式化视图。


