 Türkçe
Türkçe English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 tasarruf edin
tasarruf edinLinux’ta Redis Scan Komutlarını Kullanma: Tam Bir Rehber
Redis, yüksek performanslı, açık kaynaklı, bellek içi veri yapısı deposu olup anahtar-değer veritabanı, önbellek ve ileti aracısı olarak yaygın şekilde kullanılmaktadır. En güçlü — ancak sıklıkla yetersiz kullanılan — özelliklerinden biri, sunucunuzu bloke etmeden veya performansı düşürmeden büyük veri setleri arasında artımlı olarak yineleme yapmanızı sağlayan scan komutlarıdır.
Redis’i Linux tabanlı bir sunucuda çalıştırıyorsanız, scan komutlarında uzmanlaşmak ölçeklenebilir, üretime hazır uygulamalar oluşturmak için gereklidir. Tüm eşleşen anahtarları tek bir bloke edici işlemde alan tehlikeli KEYS komutunun aksine, scan komutları verileri küçük, yönetilebilir toplu işlemler halinde döndürür — bu da onları önemli veri hacimleriyle ilgilenen herhangi bir ortam için doğru araç yapar.
Bu kapsamlı kılavuzda, Redis’te Linux üzerinde SCAN, SSCAN, HSCAN ve ZSCAN komutlarını tam olarak nasıl kullanacağınızı, gerçek dünya örnekleri, shell betikleri ve üretim dağıtımları için en iyi uygulamalarla birlikte öğreneceksiniz.
Redis Scan Komutları Nedir?
Redis scan komutları, anahtarlar, setler, hashler ve sıralanmış setler üzerinde yineleme yapmak için imleç tabanlı, engellemeyen bir mekanizma sağlar. Her komut, çağrı başına küçük bir öğe alt kümesini ve sonraki çağrılarda yinelemeyi devam ettirmek için kullanacağınız bir imleç değerini döndürür. İmleç 0 değerine döndüğünde, tam veri seti taranmıştır.
Bu yaklaşım, KEYS komutundan temelde daha güvenli ve daha verimlidir; bu komut, tarama bitene kadar tüm Redis sunucusunu engeller — milyonlarca anahtara sahip üretim ortamlarında kritik bir sorundur.
Dört Temel Scan Komutu
| Komut | Amaç |
|---|---|
SCAN | Tüm anahtar alanındaki anahtarlar üzerinde yineleme yapar |
SSCAN | Bir Set içindeki öğeler üzerinde yineleme yapar |
HSCAN | Bir Hash içindeki alanlar ve değerler üzerinde yineleme yapar |
ZSCAN | Bir Sıralanmış Set içindeki üyeler ve puanlar üzerinde yineleme yapar |
Tarama Komutlarının Temel Sözdizimi
Dört tarama komutu da tutarlı bir sözdizimi yapısını paylaşır:
SCAN cursor [MATCH pattern] [COUNT count]
SSCAN key cursor [MATCH pattern] [COUNT count]
HSCAN key cursor [MATCH pattern] [COUNT count]
ZSCAN key cursor [MATCH pattern] [COUNT count]Parametreler Açıklandı
cursor— Yineleme içindeki geçerli konumu temsil eden bir tamsayı. Yeni bir tarama başlatmak için her zaman0ile başlayın. Redis her yanıtta yeni bir imleç döndürür; devam etmek için sonraki çağrıda kullanın.MATCH pattern*(isteğe bağlı)* — Glob stili desen eşleştirmesini kullanarak sonuçları filtreler (örn.user:*,*session*). Not: filtreleme *alındıktan sonra* gerçekleşir, bu nedenle düşük yoğunluklu eşleşmeler birçok yineleme gerektirebilir.COUNT count*(isteğe bağlı)* — Redis’e yineleme başına kaç öğe döndüreceğini öneren bir ipucu. Bu sabit bir sınır değildir; Redis daha fazla veya daha az döndürebilir. Varsayılan değer10şeklindedir.
Linux’te Redis Kurulumu
Scan komutlarını kullanmadan önce, Linux sunucunuzda Redis’in kurulu ve çalışır durumda olması gerekir. Yüksek trafikli bir üretim ortamında olsanız da, geliştirme makinenizde olsanız da, kurulum işlemi basittir.
> İpucu: Redis’i ölçekte gerektiren üretim iş yükleri için, Redis’in talep ettiği bellek, CPU ve I/O kaynaklarına sahip olduğunuzdan emin olmak için bir VPS Hosting planı veya Dedicated Server üzerinde dağıtmayı düşünün.
Debian/Ubuntu’da Redis Kurulumu
sudo apt update
sudo apt install redis-server -yCentOS/RHEL’de Redis Kurulumu
sudo yum install redis -y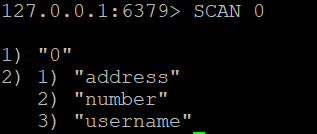
Redis Hizmetini Başlatma
sudo systemctl start redis
sudo systemctl enable redisKurulumu Doğrulama
sudo systemctl status redisÇıktıda active (running) görmelisiniz. Şimdi Redis CLI’ye bağlanın:
redis-cliCLI içinde olduğunuzda, bağlantıyı test edin:
127.0.0.1:6379> PING
PONGScan komutlarını kullanmaya başlamaya hazırsınız.
SCAN Komutunu Kullanma
SCAN komutu Redis keyspace’indeki tüm anahtarları yineler. Üretim ortamlarında KEYS komutunun genel amaçlı yerine geçenidir.
Örnek 1: Temel SCAN
Veritabanındaki tüm anahtarları taramaya başlamak için, imleç 0 ile başlayın:
SCAN 0Örnek çıktı:
1) "14"
2) 1) "session:abc123"
2) "user:1001"
3) "product:55"İlk öğe (14) sonraki imleçdir. Bunu sonraki SCAN çağrınızda kullanın. Döndürülen imleç 0 olduğunda, tam yineleme tamamlanmıştır.
Örnek 2: MATCH ile Anahtarları Filtreleme
Belirli bir desene uyan anahtarları almak için — örneğin, user: ile başlayan tüm anahtarlar:
SCAN 0 MATCH user:*Bu, yalnızca adları user: ile başlayan anahtarları döndürür. Tüm keyspace’i taradığınızdan emin olmak için imleç 0 döndürene kadar yinelemeye devam edin.
Örnek 3: COUNT ile Toplu İşlem Boyutunu Kontrol Etme
Redis’in yineleme başına yaklaşık 100 anahtar döndürmesini önermek için:
SCAN 0 COUNT 100Unutmayın: COUNT bir *ipucu*dur, garantı değildir. Redis, iç veri yapılarına bağlı olarak biraz daha fazla veya daha az sonuç döndürebilir.
Örnek 4: Shell Betiği ile Tam Keyspace Yinelemesi
Gerçek dünya senaryolarında, tüm keyspace’i programlı olarak döngüye almanız gerekecektir. İşte bir desene uyan tüm anahtarları yineleyen üretime hazır bir Bash betiği:
#!/bin/bash
cursor=0
echo "Starting full keyspace scan..."
while true; do
# Execute SCAN and capture the result
result=$(redis-cli SCAN $cursor MATCH user:* COUNT 100)
# Extract the new cursor (first line of output)
cursor=$(echo "$result" | head -n 1)
# Extract and display the keys (remaining lines)
keys=$(echo "$result" | tail -n +2)
echo "Keys found:"
echo "$keys"
# Break the loop when cursor returns to 0
if [[ "$cursor" == "0" ]]; then
echo "Scan complete."
break
fi
doneBu betiği çalıştırmak için:
chmod +x scan_keys.sh
./scan_keys.sh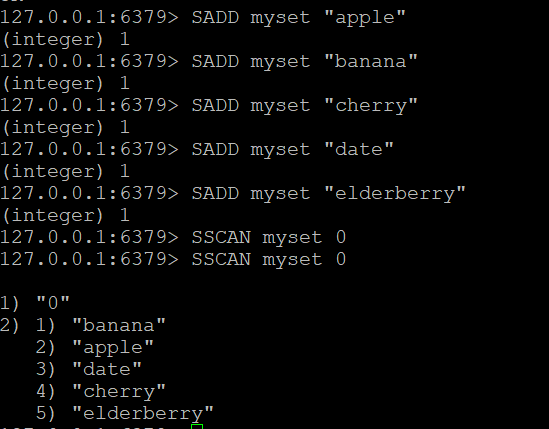

SSCAN Komutunu Kullanma
SSCAN bir Redis Set‘in üyelerini artımlı olarak yinelemek için kullanılır. SCAN ile aynı imleç tabanlı deseni izler.
Adım 1: Set Oluşturma ve Üye Ekleme
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"
SADD myset "mango"
SADD myset "mango:tropical"
SADD myset "mango:dried"Adım 2: Temel SSCAN
myset içindeki tüm öğeleri imleç 0 başlayarak tarayın:
SSCAN myset 0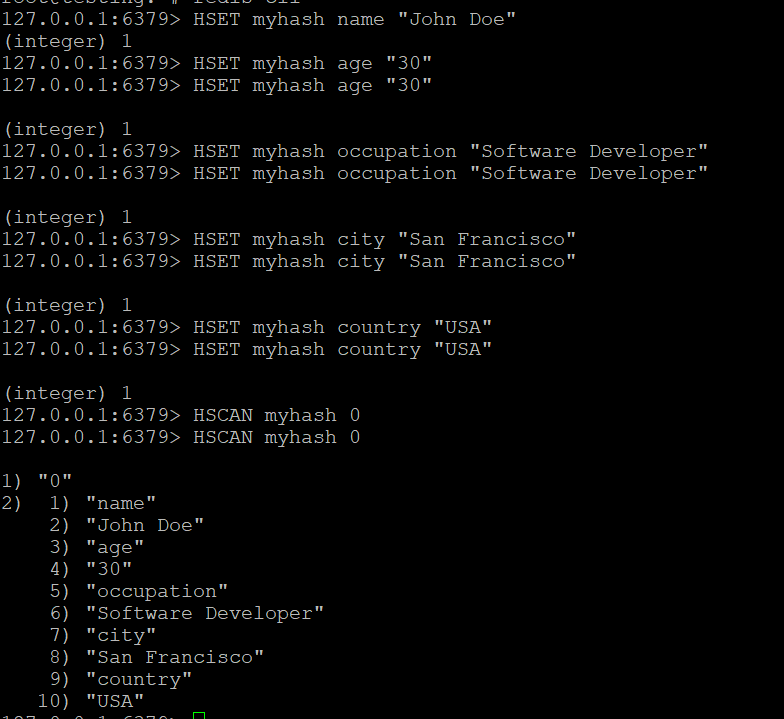
Adım 3: MATCH ile Öğeleri Filtreleme
Yalnızca mango:* deseniyle eşleşen öğeleri almak için:
SSCAN myset 0 MATCH mango:*Adım 4: Shell Betiği ile Set Üzerinde Yineleme
#!/bin/bash
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor COUNT 10)
# Update cursor
cursor=$(echo "$result" | head -n 1)
# Print elements returned
elements=$(echo "$result" | tail -n +2)
echo "Elements: $elements"
# Stop when cursor returns to 0
if [[ "$cursor" == "0" ]]; then
echo "Set scan complete."
break
fi
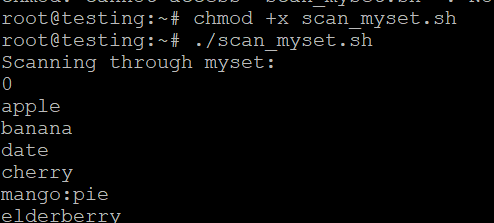
donescan_myset.sh olarak kaydedin, çalıştırılabilir yapın ve çalıştırın:
chmod +x scan_myset.sh
./scan_myset.sh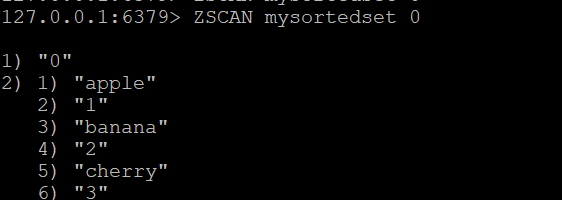
HSCAN Komutunu Kullanma
HSCAN bir Redis Hash’inin alanlarını ve değerlerini yineler. Bu, bir hash yüzlerce veya binlerce alan içerdiğinde ve bunları belleğe yüklemeden işlemeniz gerektiğinde özellikle yararlıdır.
Adım 1: Hash Oluşturun ve Alan Ekleyin
HSET myhash name "John Doe"
HSET myhash age "30"
HSET myhash occupation "Software Developer"
HSET myhash city "San Francisco"
HSET myhash country "USA"
HSET myhash email "john@example.com"Adım 2: Temel HSCAN
HSCAN myhash 0Örnek çıktı:
1) "0"
2) 1) "name"
2) "John Doe"
3) "age"
4) "30"
5) "occupation"
6) "Software Developer"
...Sonuçlar alternatif alan-değer çiftleri olarak döndürülür.
Adım 3: MATCH ile Hash Alanlarını Filtreleme
Yalnızca adları "city" içeren veya bir desene uyan alanları almak için:
HSCAN myhash 0 MATCH *city*Adım 4: Shell Betiği ile Hash’te Yineleme Yapma
#!/bin/bash
cursor=0
echo "Scanning hash: myhash"
while true; do
result=$(redis-cli HSCAN myhash $cursor COUNT 10)
cursor=$(echo "$result" | head -n 1)
fields=$(echo "$result" | tail -n +2)
echo "Fields and values:"
echo "$fields"
if [[ "$cursor" == "0" ]]; then
echo "Hash scan complete."
break
fi
doneZSCAN Komutunu Kullanma
ZSCAN bir Redis Sorted Set’in üyelerini ve puanlarını yineler. Sorted Set’ler yaygın olarak liderlik tabloları, öncelik kuyrukları ve zaman serisi verileri için kullanılır — büyük koleksiyonları verimli bir şekilde taramanın kritik olduğu tüm senaryolar.
Adım 1: Sorted Set Oluşturun ve Üye Ekleyin
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"
ZADD mysortedset 4 "date"
ZADD mysortedset 5 "elderberry"Adım 2: Temel ZSCAN
ZSCAN mysortedset 0Örnek çıktı:
1) "0"
2) 1) "apple"
2) "1"
3) "banana"
4) "2"
5) "cherry"
6) "3"Sonuçlar, alternatif üye-puan çiftleri olarak döndürülür.
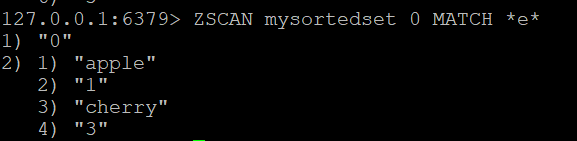
Adım 3: MATCH ile Üyeleri Filtreleyin
Adları "e" harfini içeren tüm üyeleri bulmak için:
ZSCAN mysortedset 0 MATCH *e*Adım 4: Tam Sorted Set İterasyon Betiği
#!/bin/bash
cursor=0
echo "Scanning sorted set: mysortedset"
while true; do
result=$(redis-cli ZSCAN mysortedset $cursor COUNT 10)
cursor=$(echo "$result" | head -n 1)
members=$(echo "$result" | tail -n +2)
echo "Members and scores:"
echo "$members"
if [[ "$cursor" == "0" ]]; then
echo "Sorted set scan complete."
break
fi
doneScan Command Comparison: Quick Reference
| Özellik | `SCAN` | `SSCAN` | `HSCAN` | `ZSCAN` |
|---|---|---|---|---|
| Hedef | Tüm anahtarlar | Set üyeleri | Hash alanları/değerleri | Sorted set üyeleri/puanları |
| Anahtar adı gerektirir | Hayır | Evet | Evet | Evet |
| MATCH destekler | Evet | Evet | Evet | Evet |
| COUNT destekler | Evet | Evet | Evet | Evet |
| Çıktı formatı | Anahtar adları | Üye dizgileri | Alan-değer çiftleri | Üye-puan çiftleri |
| Engelleme | Hayır | Hayır | Hayır | Hayır |
Redis Scan Komutlarını Üretimde Kullanmak İçin En İyi Uygulamalar
1. Üretimde Her Zaman SCAN Kullanın, KEYS Değil
KEYS komutu tek iş parçacıklıdır ve tamamlanana kadar diğer tüm Redis işlemlerini engeller. Milyonlarca anahtara sahip bir veritabanında, bu ciddi gecikme artışlarına neden olabilir. Üretimde KEYS hiçbir zaman kullanmayın. SCAN doğru, engellemeyen alternatiftir.
2. COUNT’u Veri Seti Boyutunuza Göre Ayarlayın
Küçük veri setleri için (COUNT 10 iyidir. Büyük veri setleri için, COUNT değerini 100–1000 arasına çıkarın, gidiş-dönüş sayısını azaltırken bireysel yanıtları yönetilebilir tutun.
3. Verimlilik İçin Yalnızca MATCH’e Güvenmeyin
MATCH filtresi, Redis öğeleri dahili olarak aldıktan *sonra* uygulanır. Deseniniz yalnızca anahtarların küçük bir kısmıyla eşleşiyorsa, Redis yine de dahili olarak tam veri setini tarar. MATCH’i daha etkili hale getirmek için anahtar adlandırma kurallarını (örneğin, tutarlı önekler) kullanın.
4. Sonuçları Toplu Olarak İşleyin
Tüm tarama sonuçlarını işlemeden önce bellekte biriktirmeyin. Bunun yerine, her toplu işi döndürüldüğü anda hemen işleyin. Bu, bellek kısıtlı sunucularda özellikle önemlidir.
5. İmleç Durumunu Dikkatli Şekilde Yönetin
İmleci her zaman 0 olarak başlatın ve her yanıtla güncelleyin. Uygulamanız tarama sırasında çökerse, 0 adresinden yeniden başlayın. Redis imleçleri sunucu yeniden başlatmaları arasında kalıcı değildir.
6. Geliştirmede Önce Kapsamlı Şekilde Test Edin
Tarama tabanlı mantığı üretim ortamına dağıtmadan önce, temsili bir veri seti ile hazırlık ortamında doğrulayın. İmleç 0 adresine döndüğünde döngünüzün doğru şekilde sonlandığını doğrulayın.
7. Redis Örneğinizi Güvenli Hale Getirin
Redis, kimlik doğrulaması olmadan asla genel internete açılmamalıdır. Redis yapılandırmanızda requirepass kullanın, localhost veya özel bir ağ arayüzüne bağlayın ve erişimi kısıtlamak için güvenlik duvarı kurallarını kullanın.
Redis için Doğru Hosting Ortamını Seçmek
Redis performansı doğrudan mevcut RAM, CPU hızı ve ağ gecikmesine bağlıdır. Doğru hosting altyapısını seçmek, verimli Redis komutları yazmak kadar önemlidir.
- Geliştirme ve küçük projeler: Paylaşımlı Web Hosting hafif Redis kullanımı için yeterli olabilir, ancak özel Redis örnekleri her zaman tercih edilir.
- Büyüyen uygulamalar: Bir VPS Hosting planı size özel kaynaklar, root erişimi ve Redis yapılandırmasını (
maxmemory, kalıcılık ayarları, vb.) tam ihtiyaçlarınıza göre ayarlama yeteneği sağlar. - Yüksek trafikli üretim sistemleri: Dedicated Servers Redis’in kullanabileceği maksimum RAM ve CPU kaynaklarını sağlayarak kaynak çekişmesini tamamen ortadan kaldırır.
- Redis’i vektör deposu olarak kullanan AI ve ML iş yükleri: GPU Hosting embedding oluşturma ve Redis ile birlikte benzerlik araması için gerekli hesaplama gücünü sunar.
Daha kolay yönetim için web kontrol paneli gerektiren uygulamalar için, cPanel’li VPS tam sunucu kontrolü ile birlikte kullanıcı dostu bir arayüz sağlar.
Sorun Giderme – Yaygın Sorunlar
SCAN Tekrar Tekrar 0 Öğe Döndürüyor
Bu genellikle MATCH deseninizin hiçbir anahtarla eşleşmediği veya veri setinin boş olduğu anlamına gelir. Toplam anahtar sayısını kontrol etmek için DBSIZE ile anahtar adlandırmanızı doğrulayın.
127.0.0.1:6379> DBSIZE
(integer) 15420İmleç Asla 0’a Dönmüyor
Bu, kararlı bir Redis örneğinde gerçekleşmemelidir. Gerçekleşirse, Redis sürümü uyumluluğunu kontrol edin (scan komutları Redis 2.8+ gerektirir) veya imleç izlemenizi sıfırlayan bağlantı kesintilerini kontrol edin.
Betik Süresiz Olarak Asılı Kalıyor
Döngünüzün redis-cli çıktısının ilk satırından imleci doğru şekilde okuduğundan emin olun. Her zaman sıfır olmayan bir imleç üreten bir ayrıştırma hatası sonsuz bir döngüye neden olacaktır.
Sonuç
Redis scan komutları — SCAN, SSCAN, HSCAN ve ZSCAN — Linux üzerinde ölçekte Redis ile çalışan herhangi bir geliştirici veya sistem yöneticisi için vazgeçilmez araçlardır. Bunlar, KEYS gibi komutlarla ilişkili performans riskleri olmadan büyük veri setleri arasında yineleme yapmak için güvenli, engellemeyen, imleç tabanlı bir mekanizma sağlarlar.
Scan komutlarını MATCH desenleri, uygun COUNT ipuçları ve iyi yapılandırılmış shell betikleriyle birleştirerek, veri seti boyutunuyla zarif bir şekilde ölçeklenen verimli veri işleme boru hatları oluşturabilirsiniz. Bu kılavuzda özetlenen en iyi uygulamaları takip etmek — özellikle üretim güvenliği, bellek yönetimi ve altyapı seçimi konusunda — Redis dağıtımlarınızın performanslı ve güvenilir kalmasını sağlayacaktır.
En güncel komut seçenekleri ve gelişmiş yapılandırma ayrıntıları için her zaman resmi Redis belgelerine başvurun. Redis’i üretim sınıfı bir Linux ortamında dağıtmaya hazır olduğunuzda, talep gören, bellek yoğun iş yüklerini işlemek için tasarlanmış altyapı için AlexHost’un VPS Hosting ve Dedicated Servers hizmetlerini keşfedin.


