Uso de los comandos Scan en Redis en Linux
Redis, un almacén de estructuras de datos en memoria de código abierto, es conocido por su velocidad y versatilidad como base de datos clave-valor. Una de sus potentes características es la capacidad de iterar incrementalmente a través de conjuntos de datos utilizando comandos de scan. Esto es particularmente útil cuando se trata de grandes conjuntos de datos, ya que permite una recuperación eficiente de los datos sin sobrecargar el servidor. Para los usuarios en un servidor Linux dedicado, el uso de comandos de scan en Redis puede mejorar el rendimiento de manejo de datos al permitir el procesamiento preciso y optimizado de recursos de conjuntos de datos. En este artículo, vamos a explorar cómo utilizar eficazmente los comandos de scan en Redis dentro de un entorno Linux, ofreciendo ejemplos detallados y las mejores prácticas para la gestión y recuperación de datos a escala …
¿Qué son los comandos de scan?
Los comandos de scan en Redis proporcionan una manera de iterar sobre claves, conjuntos, hashes y conjuntos ordenados de una manera no bloqueante. A diferencia del comando KEYS, que puede ser peligroso para grandes conjuntos de datos, ya que devuelve todas las claves coincidentes a la vez, los comandos de scan devuelven un pequeño número de elementos a la vez. Esto minimiza el impacto en el rendimiento y permite la iteración incremental.
Comandos de scan de claves
- SCAN: Recorre las claves del espacio de claves.
- SSCAN: Recorre los elementos de un conjunto.
- HSCAN: Recorre los campos y valores de un hash.
- ZSCAN: Itera a través de miembros y puntuaciones en un conjunto ordenado.
Sintaxis básica de los comandos de scan
Cada comando de scan tiene una sintaxis similar:
- cursor: Un número entero que representa la posición desde la que empezar a escanear. Para iniciar una nueva búsqueda, utilice 0.
- MATCH pattern: (opcional) Un patrón para filtrar las claves devueltas. Admite patrones de tipo glob.
- COUNT cuenta: (opcional) Una pista para Redis sobre cuántos elementos devolver en cada iteración.
Instalación de Redis en Linux
Para CentOS/RHEL, utilice:
Una vez instalado, inicie el servidor Redis:
Conexión a Redis
Abra su terminal y conéctese a su instancia de Redis utilizando la CLI de Redis:
Ahora puedes ejecutar comandos Redis en la CLI.
Uso del comando SCAN
Ejemplo 1: SCAN Básico
Para recuperar todas las claves de la base de datos Redis, puede utilizar:
SCAN 0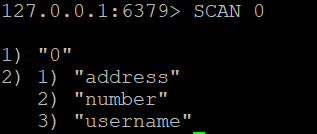
Este comando devolverá un cursor y una lista de claves.
Ejemplo 2: Uso de MATCH para filtrar teclas
Si desea encontrar claves que coincidan con un patrón específico, como claves que empiecen por “user:”, puede utilizar:
Este comando sólo devuelve las claves que empiezan por “user:”.
Ejemplo 3: Especificación de COUNT
Para indicar cuántas claves debe devolver Redis en cada iteración, puede especificar un recuento:
Esto intentará devolver aproximadamente 10 claves. Tenga en cuenta que el número real devuelto puede ser menor.
Ejemplo 4: Iteración a través de todas las claves
Para iterar a través de todas las teclas en múltiples iteraciones, necesita hacer un seguimiento del cursor devuelto. He aquí un sencillo ejemplo de script de shell:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH manzana:*)
echo "$resultado" # Procesar el resultado según sea necesario
cursor=$(echo "$resultado" | awk 'NR==1{print $1}') # Actualizar el cursor
if [[ "$cursor" == "0" ]]; then
break # Parar cuando el cursor vuelva a ser 0
fi
hechoUso del comando SSCAN
El comando SSCAN se utiliza para recorrer los elementos de un conjunto. Su sintaxis es similar a la de SCAN:
Ejemplo de SSCAN
Paso 1: Crear un conjunto y añadir elementos
Creemos un conjunto llamado myset y añadámosle algunos elementos:
SADD myset "manzana"
SADD myset "plátano
SADD myset "cereza
SADD myset "dátil
SADD myset "baya del saúcoPaso 2: Utilizar el comando SSCAN
Ahora que tenemos un conjunto llamado myset, podemos utilizar el comando SSCAN para recorrer sus elementos.
- Comando SSCAN básico: Supongamos que tenemos un conjunto llamado “myset”. Para recorrer sus elementos:
SSCAN myset 0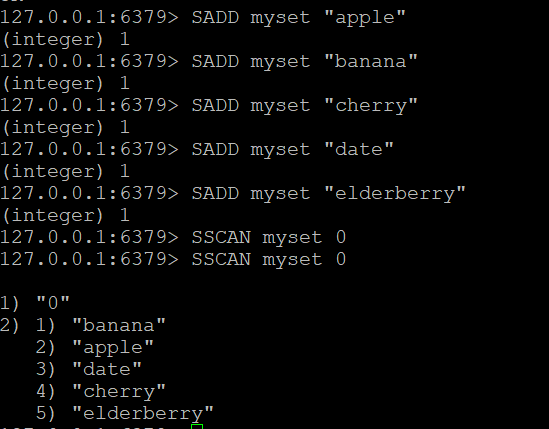
- Uso de MATCH:Para filtrar los elementos de un conjunto basándose en un patrón y añadir algunos elementos que incluyan la palabra “mango” y otras variaciones::
SSCAN myset 0 MATCH mango:*

- Iterar a través de un conjunto:Puedes utilizar un bucle para iterar a través de un conjunto :
#!/bin/bash
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor)
# Print the elements returned by SSCAN
echo "$result"
# Update the cursor for the next iteration
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Break the loop if cursor is back to 0
if [[ "$cursor" == "0" ]]; then
break
fi
donEjecución del script
Guarda el script como scan_myset.sh.
- Hágalo ejecutable:
- Ejecuta el script:
./scan_myset.sh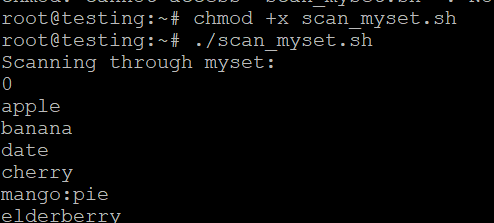

Uso de los comandos HSCAN y ZSCAN
Comando HSCAN
El comando HSCAN itera a través de los campos y valores de un hash:
El comando HSCAN se utiliza para recorrer los campos y valores de un hash.
Paso 1: Crear un hash y añadir campos
- Cree un hash llamado myhash y añádale algunos campos:
Paso 2: Utilizar HSCAN para recorrer el hash
- Utilice el comando HSCAN para recorrer los campos de myhash:
HSCAN myhash 0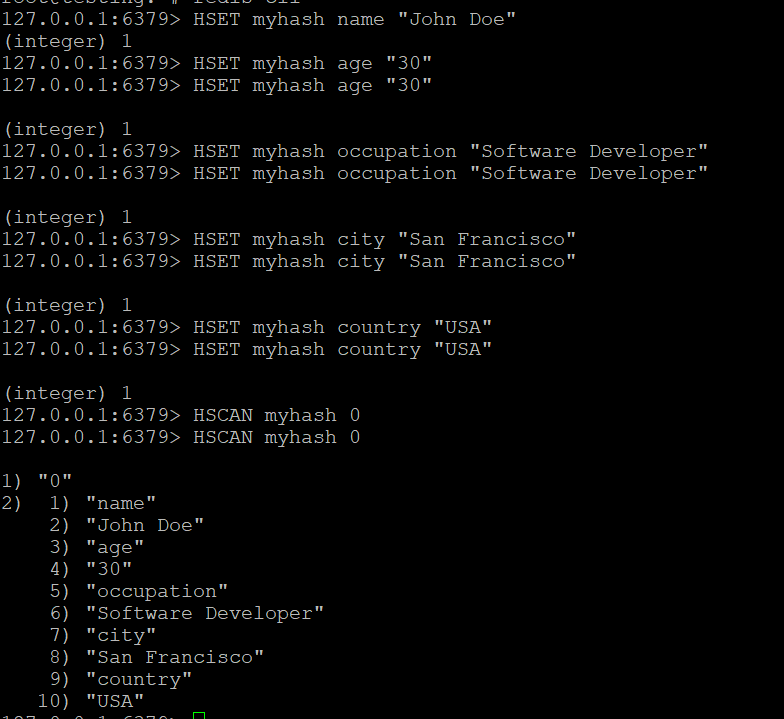
Comando ZSCAN
ZSCAN es un comando de Redis utilizado para iterar a través de los miembros de un conjunto ordenado de forma incremental. Permite recuperar miembros junto con sus puntuaciones asociadas de forma eficiente y sin bloqueos. Este comando es particularmente útil para trabajar con grandes conjuntos ordenados donde la obtención de todos los miembros a la vez puede no ser práctica.
El comando ZSCAN recorre los miembros y las puntuaciones de un conjunto ordenado:
Paso 1: Crear un conjunto ordenado y añadir miembros
Vamos a crear un conjunto ordenado llamado mysortedset y añadir algunos miembros con puntuaciones:
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"Comando ZSCAN básico:
Para iniciar el scan del conjunto clasificado, utilice:
ZSCAN mysortedset 0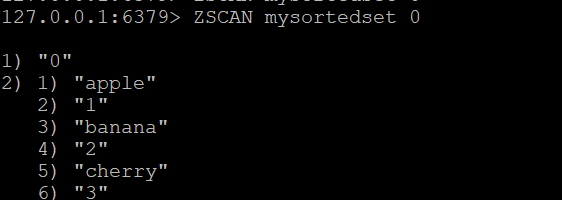
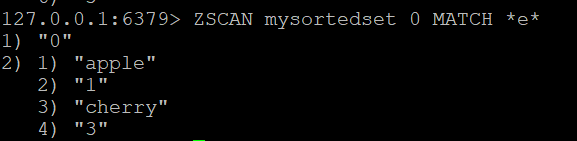
Paso 2: Uso de MATCH para filtrar miembros (opcional)
Si desea filtrar los miembros devueltos por ZSCAN, puede utilizar la opción MATCH. Por ejemplo, para encontrar los miembros que contienen la letra “e”, puede ejecutar:
ZSCAN mysortedset 0 MATCH *e*